Mux Player now supports chapters 🎉. This is super helpful if you want to split your video into titled sections, users can easily jump to the content that they’re most interested in. It’s one of Mux Player’s most requested features so we’re pretty happy to ship it.

Or, if you want to see it ✨ live ✨...
Now all you have to do is create chapters with precise timestamps for every one of your videos…
Scratch that. Let’s find a better solution that doesn’t involve that painstaking work.
AI might not be able to play Wordle yet but I bet we can get it to do some chapter segmentation for us. Let’s jump straight in.
Here’s what we’re going to be doing:
- Upload a video to Mux
- Use Mux’s auto-generated captions feature to create a captions track
- Write a small Node.js script to grab our captions and feed them into an AI LLM (large language model) for segmenting. We’ll be using OpenAI for this but you could adapt it to other models and services
- Use the AI-generated chapters in Mux Player with our initial video
On the AI side, we’re going to be keeping it simple. We’re crafting a prompt that asks the AI to analyze our captions and summarize them into chapter titles and timestamps for us. There are more advanced things you could do here — like utilizing function calling to produce a more structured output that your code validates and goes into a retry-loop if something is wrong. This is out of scope for now but something you could explore as a follow-up. We’re just aiming for a proof of concept.
Upload a video
First things first, we need a video uploaded to Mux. You can do this via the API programmatically or quickly upload one straight to the dashboard. Make sure you enable auto-generate captions on the asset before it’s uploaded.
Using the API, your POST request body might look something like this:
{
"input": [
{
"url": "...",
"generated_subtitles": [
{
"language_code": "en",
"name": "English CC"
}
]
}
],
"playback_policy": "public",
"encoding_tier": "smart"
}If you’re using the uploader tool in the dashboard instead, you’ll want to enable the captions with this option by going to Assets and clicking the ‘Create new asset’ button in the top right.

Getting set up with OpenAI
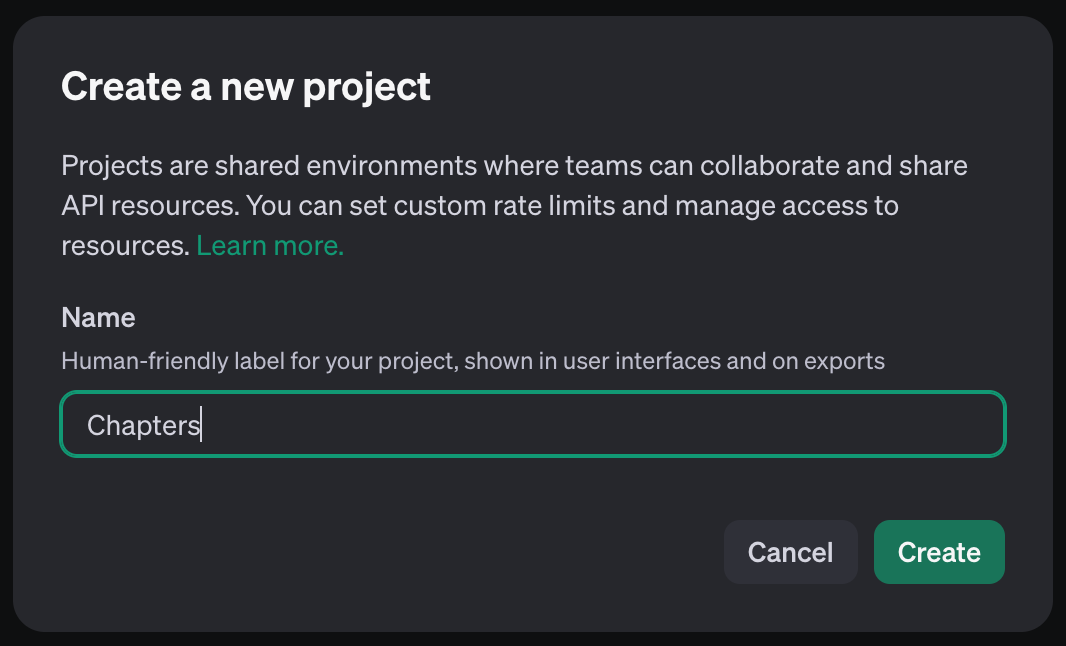
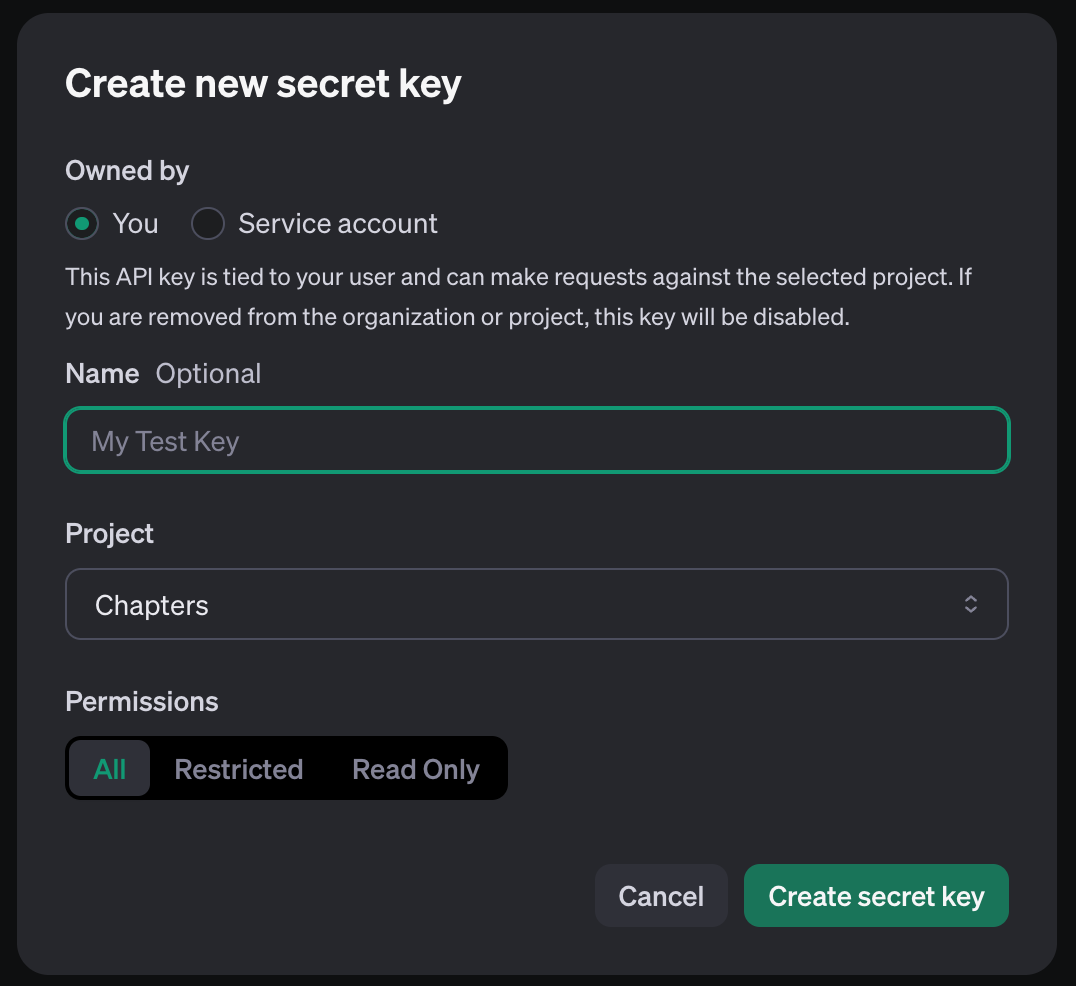
You’ll need an OpenAI account for this bit. You’ll need to do all of the following things:
- Create a project in the OpenAI dashboard
- Create an API key for that project
- Make sure your account has some credits. One thing I discovered in writing this post, new account credits expire after 3 months
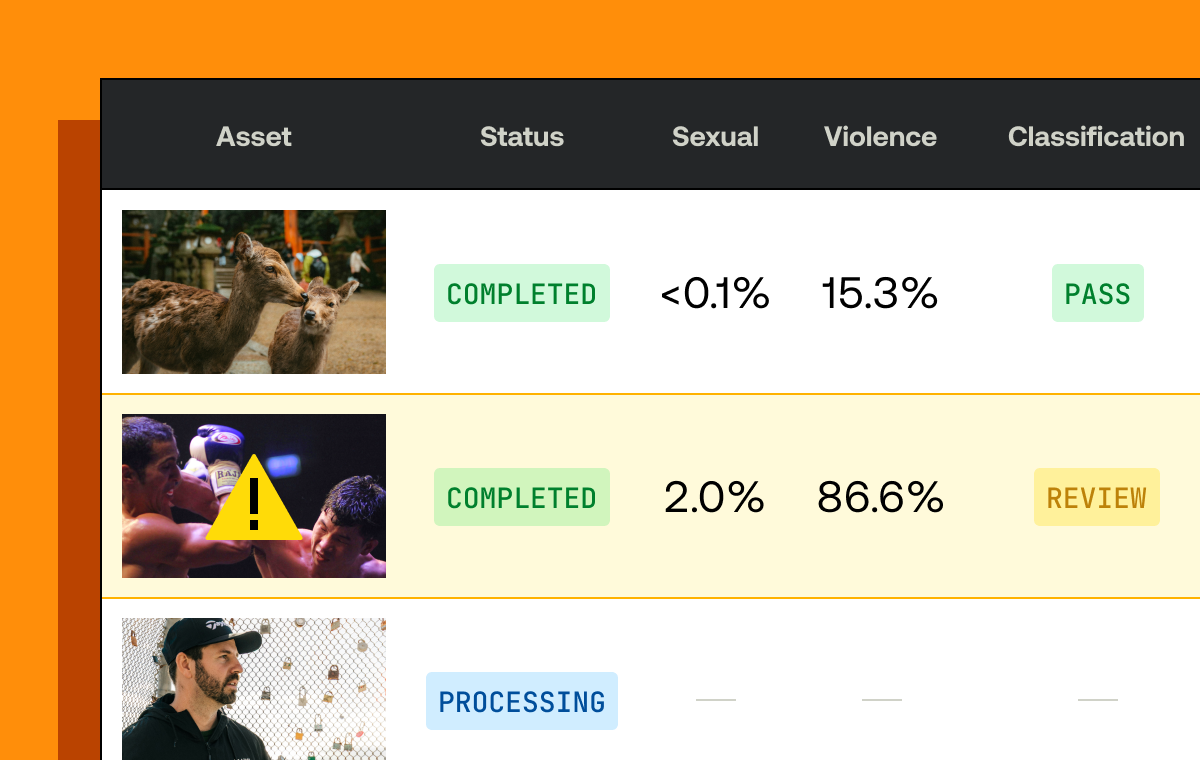
Processing the auto-generated captions and turning them into chapter markers
After uploading your video you’ll have a text track that contains the generated captions. You can see this on the asset details page in the Mux dashboard.
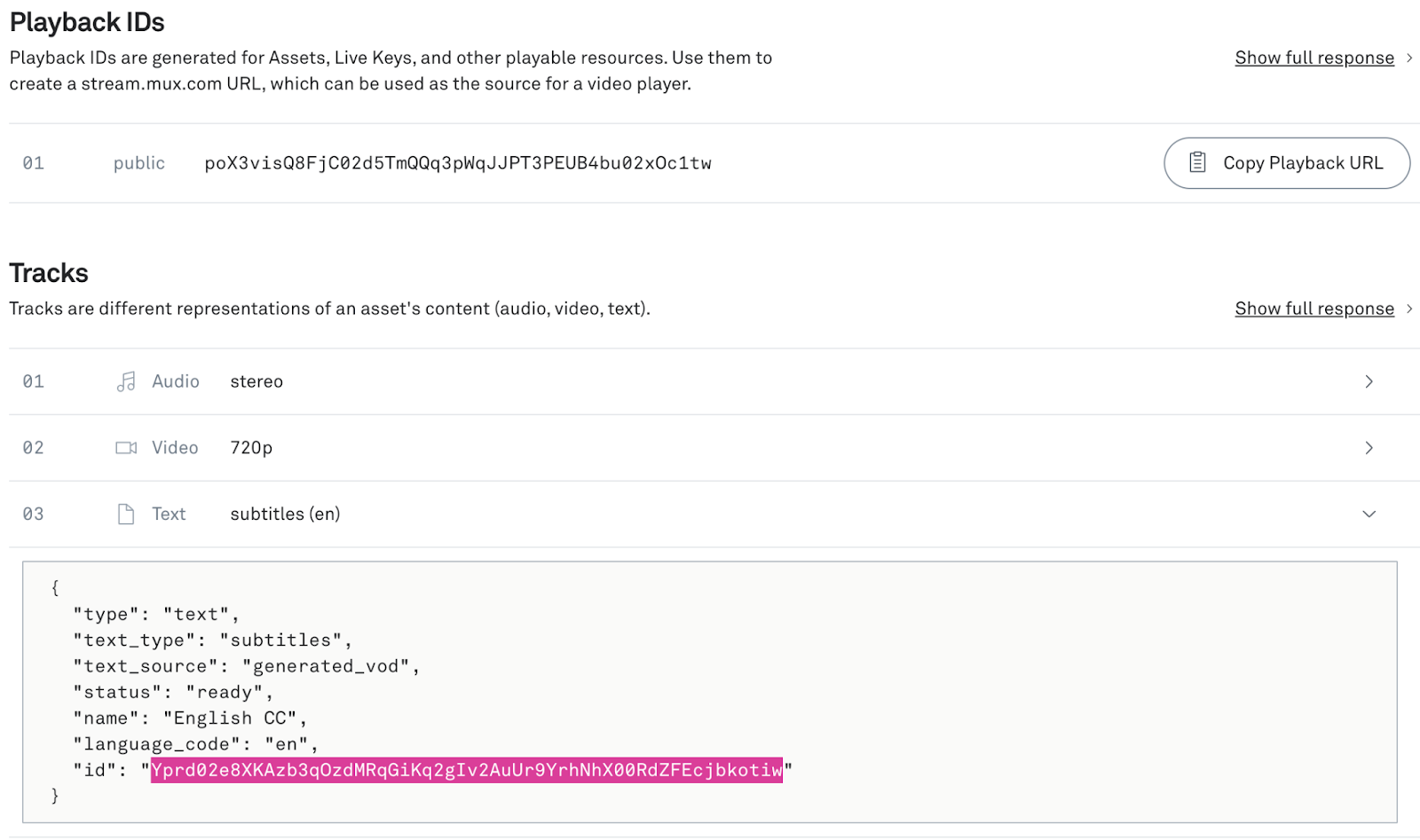
If you already have webhooks enabled you’ll also get a webhook confirming that the captions have been created (video.asset.track.ready).
Make note of the Playback ID for the asset and the Track ID (the ID highlighted in the image above) for the captions track as we’ll need them later.
We’re going to be writing a short Node.js script to fetch the captions and feed them into OpenAI’s API for processing.
Setup a Node.js project and install the OpenAI SDK:
cd ./my-project-folder
npm init
npm install openaiCreate a file called main.js, and copy this into it:
const OpenAI = require("openai");
const playbackID = '...';
const captionsTrackId = '...';
const muxCaptionsURL = `https://stream.mux.com/${playbackID}/text/${captionsTrackId}.vtt`;
const openai = new OpenAI({
apiKey: '...',
});
async function init() {
const response = await fetch(muxCaptionsURL);
const data = await response.text();
const chatCompletion = await openai.chat.completions.create({
messages: [
{ role: 'system', content: 'Your role is to segment the following captions into chunked chapters, summarising each chapter with a title. Your response should be in the YouTube chapter format with each line starting with a timestamp in HH:MM:SS format followed by a chapter title. Do not include any preamble or explanations.' },
{ role: 'user', content: data }
],
model: 'gpt-3.5-turbo',
});
const rx = /(\d+:\d+:\d+(\.\d*)?) - (\d+:\d+:\d+(\.\d*)?)? ?(.*)/g;
const matches = chatCompletion.choices[0].message.content.matchAll(rx);
const output = [...matches].map(match => ({start: match[1].replace(/\.\d+/, ''), title: match[5]}));
console.log(output);
}
init();A quick rundown of what’s happening here:
- We fetch our auto-generated captions track as a .vtt file, this includes timestamps.
- We set up a system prompt for the OpenAI call that primes ChatGPT with the task that we want it to perform, in this case, extract chapters with titles.
- We extract the start times and chapter titles from the output using a regex pattern, in case the LLM goes off the rails and includes some unnecessary surrounding text. Our regex also accounts for the LLM not returning an end time for each chapter, which it sometimes doesn’t.
- We also trim off the milliseconds from the end of the timestamp with the small regex at the end, as we don’t need them.
Before you run the script there are a few variables at the top that you’ll want to input your own credentials in: playbackID, captionsTrackId, and the OpenAI apiKey.
Running the script
Run this in the terminal to see it working:
node main.jsYou should see something like this in the console (I’ve used our instant clipping video as a test). Make a copy of the output.
[
{ start: '00:00:00', title: 'Instant Clipping Introduction' },
{ start: '00:00:15', title: 'Setting Up the Live Stream' },
{
start: '00:00:29',
title: 'Adding Functionality with HTML and JavaScript'
},
{
start: '00:00:41',
title: 'Identifying Favorite Scene for Clipping'
},
{ start: '00:00:52', title: 'Selecting Start and End Time for Clip' },
{ start: '00:01:10', title: 'Generating Clip URL' },
{ start: '00:01:16', title: 'Playing the Clipped Video' },
{ start: '00:01:24', title: 'Encouragement to Start Clipping' }
]It’s worth pointing out that the output from LLMs is non-deterministic and returns something slightly different every time you send the same query. I’ve had pretty good results so far with this script but more guardrails would need to be added if you wanted to fully productionize this.
Using our new AI-generated chapters in Mux Player
Here’s a Codepen where you can copy your generated chapters to and see them displayed in Mux Player. Just replace the chapters in index.mjs with your own AI-generated ones.
The only thing we had to do before giving the chapters directly to the player was convert the timestamps into seconds, as that’s how the player expects the chapters to be defined.
You’ll also want to input the correct playback-id for your video in the index.html.

Taking it further, some extra things you could try:
- Tweak the system prompt to change the format that the chapters are returned in, maybe you can get them returned in a way that they can go directly into Mux Player without parsing and converting the timestamps.
- Store the generated chapters, in a JSON file or a database, and load them into the player dynamically.
- Add some validation to the script that fetches the chapters so that we throw an error or retry if they’re not in the format we expect.
- We used GPT-3.5 Turbo for the model, but using one of the GPT-4 models would give you a much larger context window if you needed to process exceptionally large caption tracks.
We’d love to see your experiments when you give this a go! Reach out and let us know how you got on and show us how you’ve automated your chapter workflow.