Have you ever had to ensure that 30 million concurrent viewers were having a good Quality of Experience with your live stream? We hadn’t either. In fact, nobody had — until this past spring, when we stepped up to the challenge of using Mux Data to monitor one of the largest live streaming events in history. Ever. The event shattered existing streaming records. Here are just a few of the figures we crunched after the streams wrapped up:
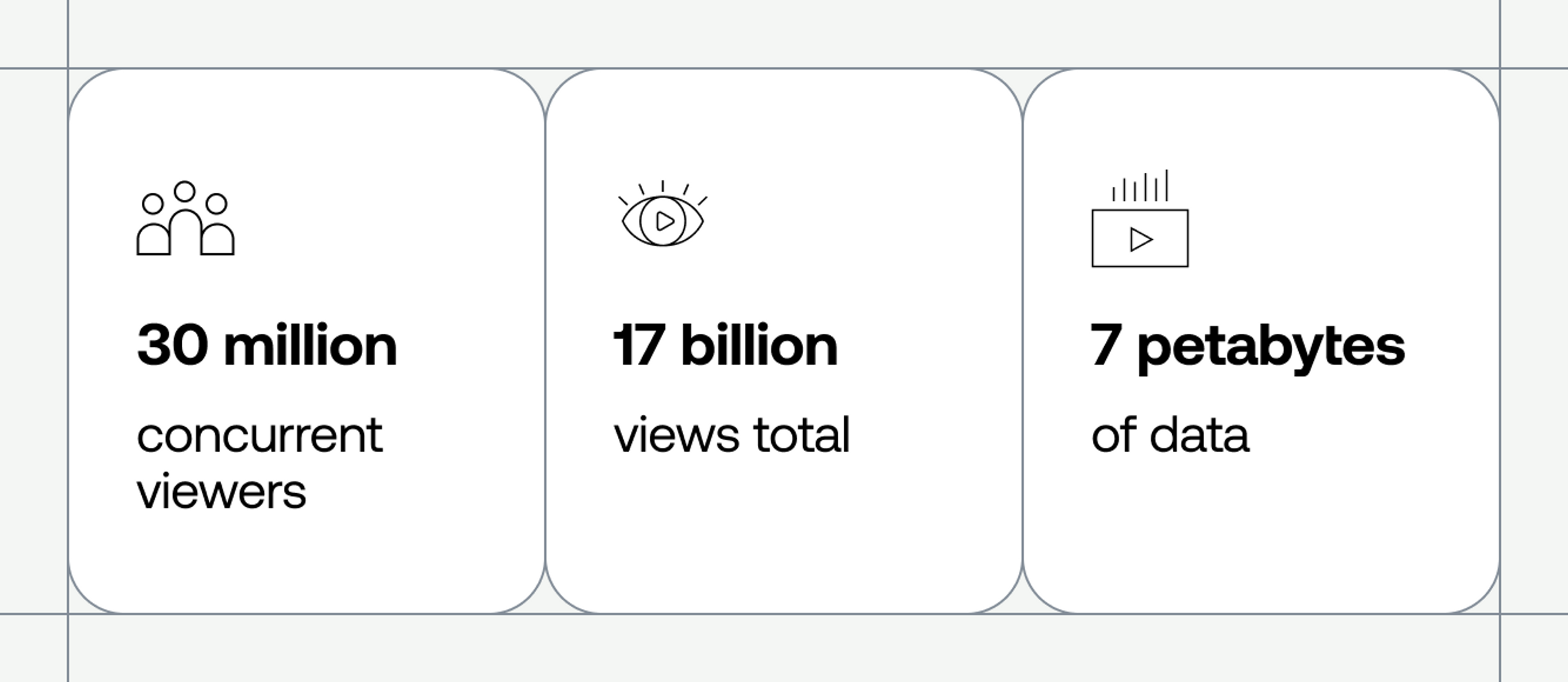
- We monitored more than 60 events across several weeks with peak viewership ranging from 8 million to over 30 million concurrent viewers.
- We processed data for almost 17 billion views across all the events.
- The system supported high-volume bursty traffic up to 3 million RPS.
- Each event ranged from 60 to 150 terabytes of event data, totaling 7 petabytes collected.
But it wasn’t all fun and games. There are months of load testing and system hardening that go into preparing for massive events like this. Here’s a look at what it takes to support monitoring live video at record-breaking scale:
Start with a very scalable architecture
First, a bit about Mux’s real-time architecture.
Mux Data collects and analyzes video Quality-of-Service (QoS) data in real time. Customers integrate Mux Data SDKs with their video player. The SDK sends playback events (e.g., playback start & end, rebuffering start & end, etc.) through load balancers to our backend collection servers. There, we parse the events and enqueue them on a Kafka cluster for asynchronous processing.
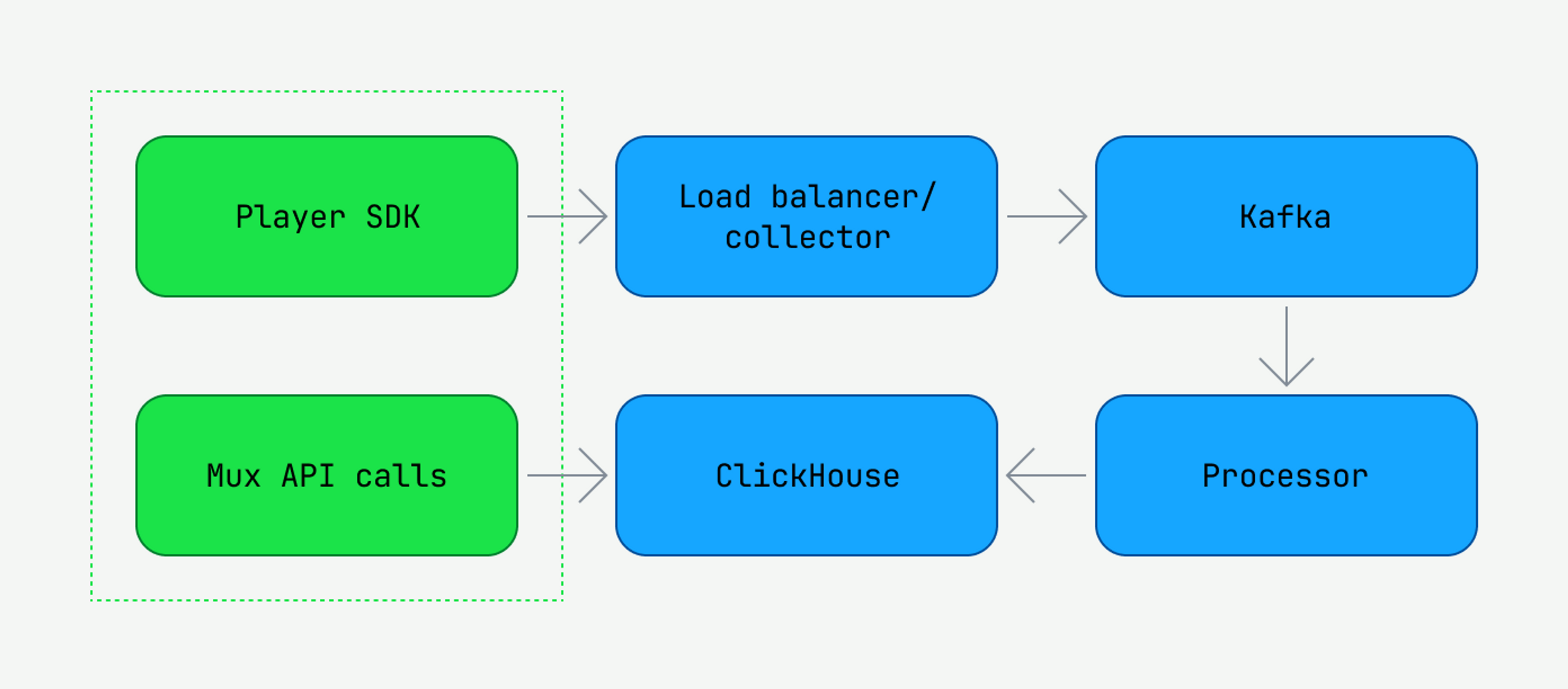
Playback events are then processed by a scalable number of "processor” services that read Kafka topics and build up a representation of each active view by accumulating the view events. The processor services write real-time data to a number of distributed analytics database services, mostly based around the open-source Clickhouse database, which is accessed by Mux Data customers via our API or monitoring dashboard.
Make everything single tenant, and scale it horizontally and vertically
With only a few months available for preparation, we didn’t have time for major rewrites or architectural changes. We had to scale out the current system.
Our first step was to deploy a separate ingestion pipeline. This helped us isolate any changes that were specific to this event and minimize any potential impact on other customers. Scaling event collection and processing for this separate pipeline was relatively straightforward, since those are stateless services that easily scale horizontally. Scaling Kafka and ClickHouse vertically took more planning and testing.
Load test the system architecture
You can have an idea that the infrastructure you’ve come up with is going to work well, but the only way you’ll truly know if it will scale is by sending traffic through it. However, it’s probably not a great idea to start sending huge amounts of production traffic through a system without prior testing. That’s where load testing comes in. If you’re unfamiliar with load testing, it’s kind of like throwing a bunch of rocks at a window to see if it will withstand the oncoming challenge.
Having a separate ingestion pipeline allowed us to perform a whole suite of load tests, with up to 50 million concurrent simulated views, before the event began. Load testing uncovered many infrastructure bottlenecks. For example, we saw our Kafka brokers hitting the network bandwidth limit and EBS volume bandwidth limits. We tested several solutions before settling on changing the compression algorithms as well as the AWS instance types.
We found another limit when it came to AWS load balancers. For this level of traffic, we needed to augment our ingestion pipeline to use multiple AWS classic load balancers (CLBs). But we found that as traffic scaled upwards, these additional CLBs wanted to consume more subnet IPs than we had available.
In contrast, AWS network load balancers (NLBs) can support much larger amounts of traffic with a static IP. They also do not need to be “prewarmed” the way CLBs do (i.e., configured by AWS Support to have the appropriate level of capacity for bursty traffic). We had been considering switching to NLBs for a while and felt this was the right time to make that change.
Watch performance under real traffic conditions
Ultimately, load testing can only get you so far when it comes to one-of-a-kind traffic events. There’s only so much mocking you can do. At some point you’ll have to start sending your production traffic through.
A serious challenge with the traffic was not just its size, but its shape and behavior. As we’ve mentioned before, the performance of our system changes based on the traffic it receives. During the Super Bowl, many viewers within the US have high-bandwidth connections that are close to our collection data centers. Not so for traffic outside the US or viewers with lower-bandwidth connections.
For this event, the majority of the traffic didn’t mimic the Super Bowl audience. As a result, we saw an increased percentage of latent requests. To make sure we didn’t DDOS ourselves with high-latency traffic, we (1) set more aggressive timeouts server side and (2) tuned the client-side retry behavior to back off more quickly.
Flexibility is paramount
Should you load test for large events like this? Absolutely. But even with a ton of load testing, you are likely going to find other ways to improve once you better understand traffic patterns. Starting with a flexible microservice architecture and having lots of previous experience with live events like the Super Bowl made it possible for us to support unprecedented scale this year (around 5x bigger than our previous record.) See you at the next game!