AI models like Whisper and OpenCLIP are making image tagging and speech-to-text transcription, two tasks that once required a team of PhDs, seem trivial — but, whew, are they expensive!
…Or are they?
Some napkin math for using these models hosted by third parties to auto-generate captions on all videos uploaded to Mux had us worried. Other third party providers currently price access to their Whisper models at up to $0.006 per minute — which seems cheap, but for a business like Mux, that $0.006 per minute isn’t a trivial addition to our per-minute costs. We already feel like video is too expensive, so passing that on to our customers felt like a non-starter.
Given these fees seemed like they’d be restricting, we also assumed it’d be prohibitively expensive to self-host these models at our scale. We were wrong.
Here’s how we were able to start offering auto-generated captions on all videos uploaded to Mux for free to all of our users.
Using the GGML tensor library
When we started our search for options, we discovered GGML, an open source tensor library for running large AI models on commodity hardware. GGML has been made popular by the implementation of both llama.cpp and whisper.cpp. It’s a game-changer in the realm of AI development, particularly in terms of cost-effectiveness.
GGML’s innovative approach optimizes the utilization of CPUs, offering a stark contrast to the traditionally GPU-centric methodologies. This emphasis on leveraging CPU resources efficiently translates into a remarkably cost-effective solution for deployment. There are even pre-built wrappers around a variety of different models so they can be run locally. The existence of these wrappers makes it incredibly easy to just plug them in and start testing out models.
GGML helped us to get started quickly without messing around with GPUs, and there is also a command line wrapper that makes it easy to get up and running. Both of these helped us get to an MVP quickly to see what Whisper could do.
The first results for using Whisper were fantastic, so we decided to do a more serious evaluation of how to generate captions efficiently. We were particularly impressed with how well Whisper handles capturing technical information without any custom dictionaries or further instructions.
Model size vs accuracy tradeoffs
Naturally, larger Whisper model sizes have more parameters, the internal variables of a model that are learned from training data. As a result, the output quality of a single model architecture using Whisper Large is generally going to be better than what you’d get leveraging Whisper Medium, with a decreased word error rate (WER) as the model grows.
By using a smaller model size, you might guess that the output quality wouldn’t be nearly at a level of confidence that is ready for a production pipeline. However, we found that smaller models still exceeded the expectations of our customers for the majority of content coming through Mux. This was great news for keeping costs low, but also meant our time to output was pretty snappy. With this setup, most transcription jobs were completed at around 0.1x the duration of video.
Was there anything else we could do to get even better performance out of this workflow?
One rudimentary idea was to break up the audio into smaller chunk files and run the job across these files in parallel. There were two obvious risks at play:
- Whisper no longer would have access to the context clues of words that were split off into separate audio clips, making it much more difficult to predict what the speaker was trying to say.
- Without leveraging a more complex sentence splitting detection algorithm, there would be a good chance that words would be split across multiple audio clips right in the middle of the word being spoken, resulting in mangled audio
A basic parallel approach would give us faster results with a tradeoff of lower quality results. But would the results still be acceptable? We had a hunch this experiment would not go so well, but we had to rule it out.
It didn’t take long to do so.
In one test with Whisper.cpp, we ran the ubiquitous jfk.wav through this approach and ended up with a less-than-ideal transcription:
[00:00:00.000 --> 00:00:02.020] And so my--
[00:00:02.020 --> 00:00:02.250] fellow Americans.
[00:00:02.750 --> 00:00:04.750] Ask not
[00:00:04.750 --> 00:00:05.120] F***!
[00:00:05.500 --> 00:00:07.020] your country can do.
[00:00:07.020 --> 00:00:07.650] for you.
[00:00:08.250 --> 00:00:10.250] Ask what you can do.
[00:00:10.250 --> 00:00:11.620] for your country.
whisper_full_parallel: the audio has been split into 8 chunks at the following times:
whisper_full_parallel: split 1 - 00:00:01.370
whisper_full_parallel: split 2 - 00:00:02.750
whisper_full_parallel: split 3 - 00:00:04.120
whisper_full_parallel: split 4 - 00:00:05.500
whisper_full_parallel: split 5 - 00:00:06.870
whisper_full_parallel: split 6 - 00:00:08.250
whisper_full_parallel: split 7 - 00:00:09.620
whisper_full_parallel: the transcription quality may be degraded near these boundaries
whisper_print_timings: load time = 12478.69 ms
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: mel time = 1863.05 ms
whisper_print_timings: sample time = 376.38 ms / 29 runs ( 12.98 ms per run)
whisper_print_timings: encode time = 447092.88 ms / 1 runs (447092.88 ms per run)
whisper_print_timings: decode time = 35315.32 ms / 27 runs ( 1307.97 ms per run)
whisper_print_timings: total time = 515866.31 ms
real 8m36.073s
user 50m0.293s
sys 8m6.556sUltimately, we decided to not parallelize these blocks, and instead we chose to do our job in serial which offered an acceptable job latency for our customers.
CPUs aren’t dead yet
For us, it turned out to be cheaper to continue to use GGML over setting up GPUs for transcription.
Is GGML slower than a GPU? Yes.
Do GPUs have higher throughput? Also yes.
However, for the same price per hour of GPU use, we can get a spot instance for an entire day. When we did cost modeling for CPU vs GPU, we found that running small models on a CPU is way cheaper than running them on GPUs.
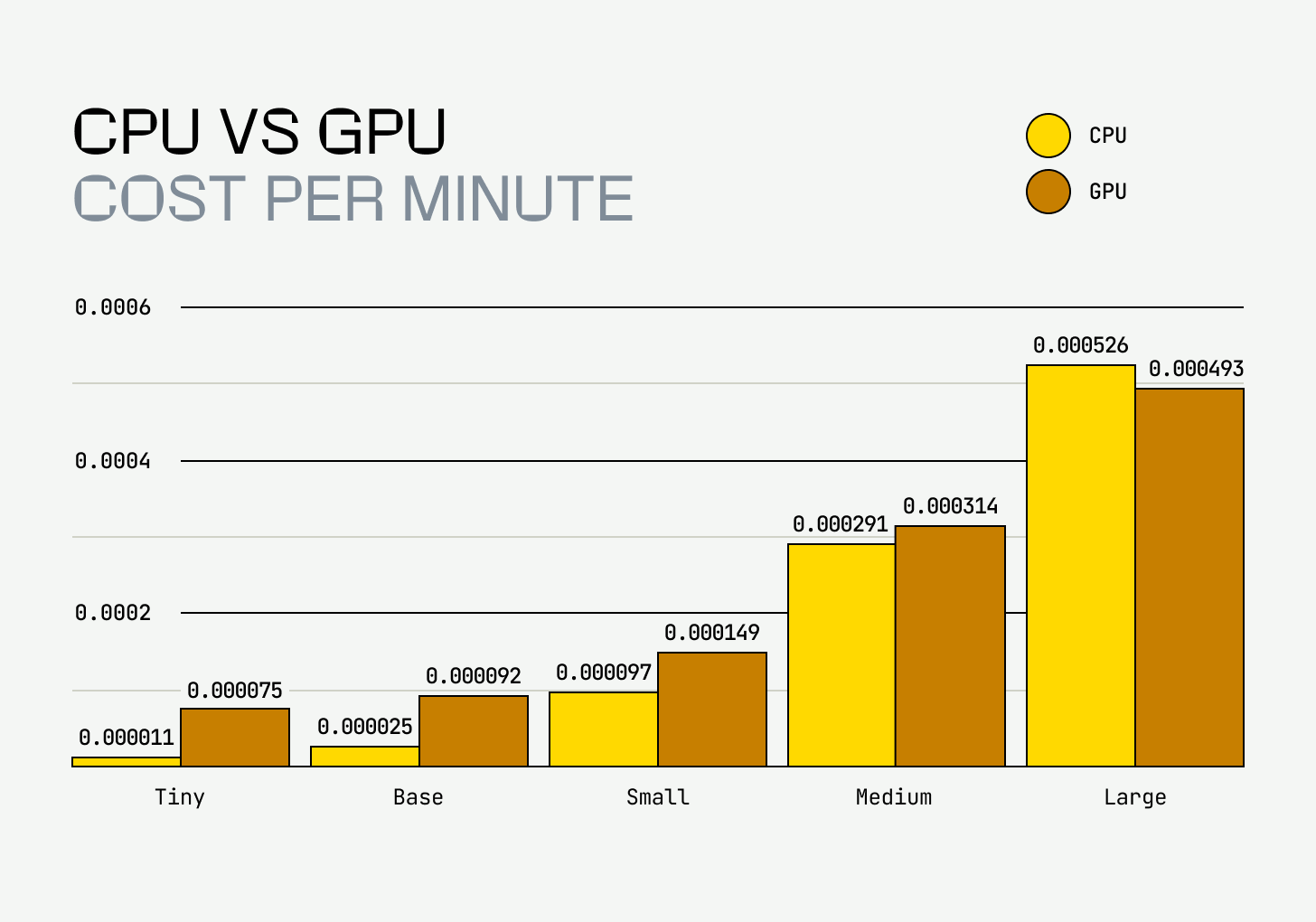
The price for running Whisper per minute of audio is cheaper on CPUs for everything except the largest model. This is likely to be the same for other small generative models. For models with under 1 Billion parameters, it might be cheaper to run inference on CPUs. For models with more than 1 Billion parameters, it might be cheaper to run them on GPU.
For models like the Whisper Base or even Whisper Small, the model isn’t even over a few hundred megabytes in size. This makes Whisper something that runs great on CPUs.
Additionally, while we are comparing prices, the cost of running models on CPU and GPU were both an order of magnitude cheaper than using a third-party API.
Okay, this all sounds great, but there’s a big elephant in the room. Wouldn’t we need some complex infrastructure in place to be able to manage this kind of workflow at scale? If only we had worked tirelessly for years on providing a battle-tested async infrastructure where this type of framework could hum right along…
Wait a second… don’t we transcode videos at scale?
Part of what made the CPU decision easier was our existing infrastructure. We have already built infrastructure for running an enormous amount of transcode jobs efficiently on CPUs. Given the Whisper model doesn’t need to run with a latency on the order of 100s of milliseconds, we can schedule jobs efficiently and asynchronously. Rather than having to run these jobs on a new hardware tier, we can just bin pack them in with our transcode jobs.
We even get the benefit of data locality because our infrastructure is great at scheduling jobs near the data while maintaining CPU utilization. There is no such infrastructure for GPUs at Mux. In the same way that many billions of transcode jobs run, we can easily pack in some Whisper jobs to run our CPUs.
All this, and more, for free
The conclusion of all of this work is the launching of Mux Automated Captions for VOD, now supporting 20+ different languages.
The best part? We’re able to offer our VOD auto captions to all Mux customers for free because of how low we were able to get the cost of providing captions.
The future of AI in video is promising, and this is just the beginning of our exploration in bringing meaningful features that help our customers build better video.