
The venerable Nick Chadwick spoke at Facebook's Video @Scale about Mux's approach to per-title encoding using machine learning. If you missed @ Scale, here's a recording of the talk along with a transcript. If that's not enough Nick for you, he also gave a similar (but more informal) talk at SF Video.
Video @Scale 2018 - Nick Chadwick, MuxNick Chadwick, Software Engineer at Mux, discusses per-title encoding for videos. Posted by At Scale on Friday, May 25, 2018
Transcript
Hi, my name is Nick Chadwick. I'm a video engineer working at Mux. Today I'm gonna be talking about per-title encoding at scale. I had a funny title on there, but I'm not gonna use it. I'm gonna be going over what is per-title encoding. I'm gonna be talking about why it matters. I'm gonna go over some practical approaches that you can use in your encoding pipeline to actually implement a per-title approach. I'm gonna talk about Mux's rad new approach using machine learning for doing per-title encoding. I was gonna chat a little bit about what's next. Hopefully, when I cram it in in time to like get everyone out to a drink as soon as possible.
Ok...and hopefully, I'm not gonna step on Netflix's toes too much because they kind of, in December 2015, dropped this blog post, and basically threw it out that everyone was doing encoding wrong. And if you read through that blog post and take a look at what they were saying, there was a fundamental assertion in there, which is that there is no one size fits all approach to encoding content. If you wanna do a great job of your encodes, each piece of content that you encode requires a different ladder to maximize its quality. And what they talked about was there being a convex hull of quality bit rate curves that if you follow, you can maximize your quality.
I'm gonna dive into that convex hull in a little bit more detail. So, what I'm gonna do is I'm gonna explore the space of video quality. I'm gonna do about three and fifty different encodes. I'm gonna use a bunch of different widths picked from the Apple bitrate ladder and Netflix's blog post. I'm gonna use a bunch of different bitrates starting at two hundred kilobits and increasing by ten percent or rounded up to the nearest fifty kilobits. I'm gonna use some pretty standard high quality encoding x264 parameters. I'm gonna use two pieces content.
One of them is a high complexity scene of the boat and water, you might notice this from the [unsure] videos, and the other one is a fairly low complexity scene of the drone flying over a city. Here's what the space looks like for the high complexity piece of content. I'm using VMAF what on one axis I have bit rate, on the other I have the width. You can see that I've got the quality color coded from the dark red of awful quality to the the dark blue with good quality, which we don't actually get to at eight megabits here at all. And you can see I've highlighted in red the convex hull that is at each bit rate, if you wanted to maximize the quality at that bit rate, you would need to use the corresponding width in order to do that. And you can see that it takes a meandering path up and it only ever gets to seven twenty p at eight megabits. It doesn't even hit ten eighty p, that's how complex the content is.
In case you're wondering if this is VMAF artifact, it's not. I ran the same same data, same encodes, evaluated using SSIM and evaluating evaluated using PSNR. And you can see that even though the exact convex hull shifts depending on the metric, we still get that same property. And if we follow that red line, we can optimize for the given metric. Now look at what happens when I do the same thing with a low complexity video. The curve looks completely different and you can see even at two hundred kilobits, there's a distinct curve where we start if you wanted to maximize quality, you have to start at a width over 800 pixels wide. And very rapidly, we move up all the way to 1080p.
You can see here that down at the lower resolutions, if you wanna maximize quality, there's absolutely no reason to ever create or serve them. Also it's very unintuitive that this piece of content looks best at 1080p at one megabit, but it does. Something very similar happens with SSIM. The curve looks almost exactly the same. Like I said, this is not an artifact of any one approach to measuring quality.
With PSNR, a curve is a little flatter, but still maintains that same shape and crucially moves up to the higher resolutions much much faster. Here's what those curves look like in 2D. You might have seen something similar to this where the bottom I have the bitrate on the y axis, I have the width that will maximize quality for the piece of content, red is high complexity, blue is low complexity and you can see that the shapes of these curves are completely different.
What can we do with this data? Well, given a bitrate, you can follow the red line to maximize quality by varying resolution. Given a resolution, you can maintain a target quality by varying the bit rate. That's kind of like doing a CRF-style encode, if you're familiar with x264. Or given a target quality, we can minimize the bit rate to deliver that quality by varying resolution.
So why does this matter? Well, it's the first one that matters most to us who are delivering things like HLS or Dash where we're delivering an an ABR set of encodes to our players so they can switch based on their bandwidth available to them. And what we wanna do is deliver encodes that maximize quality.
This is why it matters.
Let me show you this on on the left hand side here, I have something that roughly matches the Apple bitrate ladder where we're like 100 kilobits off here or there. But that's the Apple bitrate ladder. Then, I compare it to doing an encode using our best resolution and you can see here that across the board, especially for a high complexity, especially higher bitrates, our high complexity content looks better. It looks better with SSIM. It looks better with PSNR.
With our low complexity content, we get a dramatic increase at lower bitrates in quality. We're getting almost ten VMAF points all the way up to like 1.5 megabits. That is very noticeable to your users.
The same thing happens with SSIM. The numbers with SSIM are a lot smaller. I don't really understand SSIM, I'm gonna be honest about it. But PSNR, I do understand and at two megabits, we're still getting two PSNR points higher. That's great.
Okay, let me show you. Don't believe the numbers, believe your eyes. You can probably tell which one of these looks better. I hope. The one on the left is using the standard Apple bitrate ladder recommendation. The one on the right is using our optimized bitrate ladder. You can see how much crisper it looks.
Here, I do the opposite. With our high complexity content, I show you that at almost six megabits our 1080p has the same visual quality as an under five megabit encode at 1024x576. You're not meant to be able to tell a difference between these two encodes. But if you delivered that higher bit rate rendition to your users, you would be wasting a megabit of their bandwidth for no perceptual gain.
Okay, so hopefully I can convince you that it matters. How do you do it? Well, option number one is brute force. You generated a set of encodes like I did. I generated like some like 350 encodes per clip. You don't need to use that many, a lot of them are wasted. And then you searched through that space for you desired encoding properties.
The pros of this approach are it's parallelizable and very straightforward. The cons of that, it wastes a lot of resources. Option number two is kind of a different of approach to this.
You can see that as we add more bits, we only ever move up in bit rate in resolutions. We never could've kind of moved out. So we can flip that on its head and just search. We can tightly walk the convex hull. We can start with ten megabits and 1080p compared to 720p, pick the winner and move down a bitrate step by step. Let me try and show you with a diagram how that works. Here, at ten megabits, we compare 1080p to 720p. 1080p wins. We moved down.
Then we do another comparison. 720p wins. We move down and now now we just ignore 1080p because we know that it's never gonna be relevant and we moved down to comparing it something like 540p etc. And you can do this all the way down.
Now, the benefits of this approach that it's fairly efficient. For each bitrate you test, you only need to do two encodes. Maybe three if you wanna be super thorough, but but we didn't and it's fairly flexible. You can trade off accuracy of finding your convex hull for using less encodes. Or conversely, you can use more encodes and get a more accurate curve.
The bummer about this is it does require good rate control to actually work. It works great with things like x264 where there are great rate control modes where you can do a 2-pass encode and tightly hit a target. With x265, yeah, you can still do it, VP9 maybe not...and it's not easily parallelizable. It's quite a linear process and it's quite slow. You can do two encodes at once, then you need to wait, compare them and then step down. So, time wise, it does have quite a large latency.
Finally, you can try to approach this from a different perspective, where you do something like CRF encode and then use that data as a scale of some kind. The pros of this approach are that, again, it's really straightforward to implement and it's really fast. The cons are we couldn't get it to work. We couldn't find a reliable mapping between CRF and the optimal convex hull for our content, especially when we were using VMAF as our primary metric. We really like VMAF at Mux. We've evaluated it compared to SSIM and PSNR. We found the results are much more visually pleasing across a broad range of our content, which is why it's our primary metric, but we couldn't get CRF to map neatly into that space.
Okay, So what we're actually doing is a machine learning and skipping all three of these approaches. Here's how we did it. I teamed up with another Muxologist, called Ben Dodson, who has the pro of being a data scientist but not a video engineer and with our powers combined, we created a new model to efficiently estimate convex hulls so that we didn't need to do any work at all. We built a smallish data set. I know it's Video @ Scale, and it's five hundred clips. Like, oh yeah, it's video scale. No, it's only five hundred clips. It's not not proper scale yet, but the results we've gotten from this approach are really great.
What we did was we took the five hundred clips, walked the convex hull using that tight, efficient approach. We tested about 54 bitrates, two encodes per bit rate and used VMAF, which is pretty slow. We would love to get our hands on a foster VMAF. And yeah, I took about a 140 days of processing which for like me was a lot but like for most of the people in the room was like, "it's like two seconds of processing time." Yeah, I know. Okay, we're working on it.
Then we leveraged pre-existing models very heavily to basically cheat this. We try to use as much transfer learning as possible. So we started with a first neural net built on top of Inception where you like cut the last layer of the neural network off because you're not interested in the classification. What you're interested in is taking a frame from a video and turning into a interesting vector representation of the content.
Then, we trained a second neural net on the YouTube 8M data set which is similar to Inception, but specifically for classifying video content. We feed this model frames usually sampled at one FPS or lower depending on the length of the content. And that transforms are multiple frames from being images to being vectors to being a single vector, which we then trained an LSTM on to output our final convex hull estimation.
Now, we just put a blog post up today on the Mux blog, if you're interested in learning more about the machine learning side of that. I'm the video engineer not the the machine learning engineer or data scientist. So I can't speak as deeply to these parts, but basically what we did was we compared vectors that we were outputting through our model to our ground truth vectors and use mean squared errors, a lost function just to fit to our curves.
The results we have got were great. On 84% of our test set, we got better results using our convex hull estimation for our encoding then by using a static ladder. There was like 4% of videos that looked strictly worse than the others which is kind of a wash.
So we built it into Mux video! It's live. It's behind the flag called per-title encode and it currently runs significantly faster than real time. It's not as fast as we'd like it, but it's it's pretty fast. We can usually do an hour long piece of content in about a minute to generate the convex hull estimation compared to hours and hours of encoding time.
Here's a diagram that I don't fully understand, but my colleague, Ben, told me that for the machine learning engineers in the room, this would help.
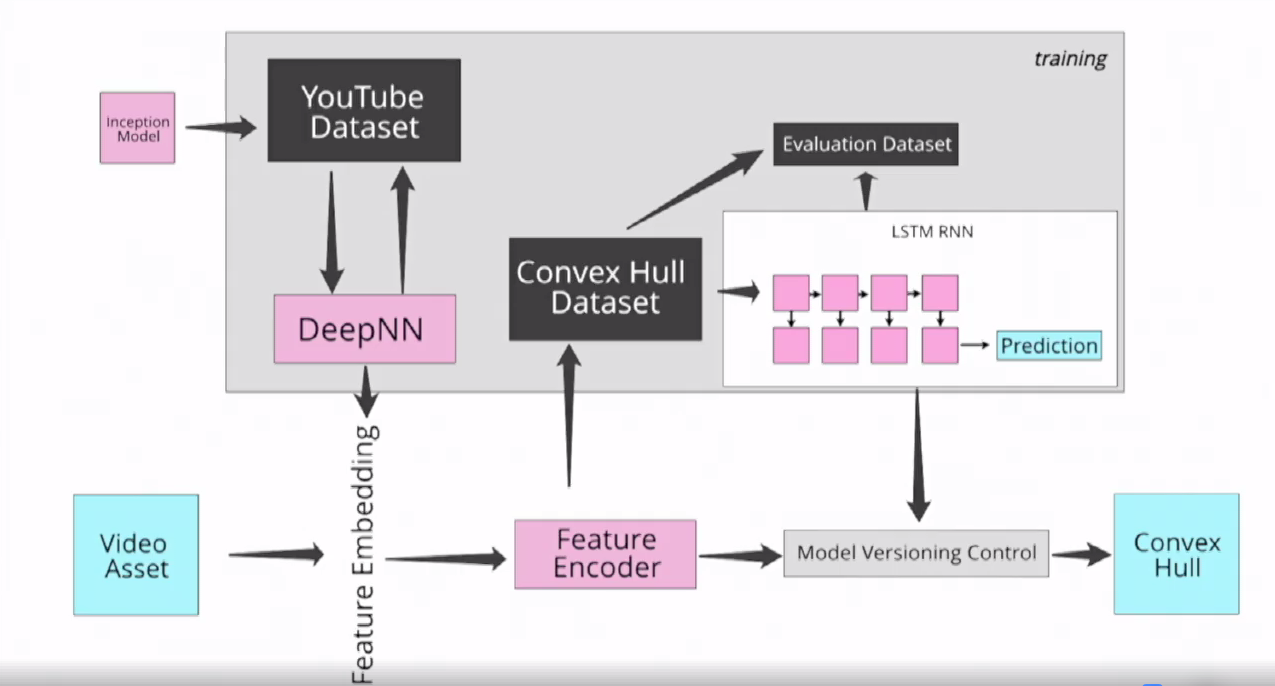
- You can see that we use Inception.
- We used the YouTube data set.
- We trained a deep neural net on it.
- We created our own convex hull data set, which we then pulled out an a evaluation data set from.
- We trained an LSTM recursive neural net to make our predictions. That way each prediction is based on the previous one so that we have this this nice property being strictly monotonic in our decrease. We don't like say 1920 at five megabits. Then 720 at six, then 1920 at eight. That was happening in our first attempt at this.
So we've made it live as I said, you can just test this out on our Mux.com homepage if you'd like. You just have to add the per_title_encode flag to true and you can see how if you just grab the m3u8 that we generate for your videos, you can see how we're doing our encoding. It's pretty public. And if you sign up for an account and want to learn more, we'll actually give you the encoding ladder. The full convex hull estimation for your videos if you wanna test this out.
So what's next? Well, the first one is more training data. We only tried five clips of this. We tried to get a very varied test set. And we used transfer learning to make sure that we were getting great results. My colleague Ben tells me he'd like that to be more like fifty thousand training clips just what we're working on.
We're looking on improving up performance, especially for our shorter clips. Getting a convex hull estimation in one minute for a one hour long video, that's fine. Honestly. But for a thirty second clip, we really like to keep our ingest times down to like five seconds. But with some of the overhead of the model, we take twenty seconds now. So it's one of the next things where it gonna be trying to work on.
There's no reason that the same approach of estimating the convex hull won't work well for new codec. Although we haven't tried those yet. We don't support them at Mux yet. It's something we're working on.
We're thinking about open sourcing this. We think that per-title encoding is pretty much gonna become table stakes over the next year two. What we'd love is to get people testing out our model and throwing us new training clips and telling us why our model is broken so we can make it better. And if open sourcing is the best way to like get feedback from that, we're we're happy to do it.
We're also working on better bitrate selection. The reason we are so interested in this is unlike other approaches where you might say, Okay, I'm gonna have a fixed resolution ladder and scale your bitrates based on the complexity of the content. We really believe that bitrates are a fundamental property that users come to you with. A user on her mobile phone who has 1.5 megabits doesn't care that your two megabits, 720p looks really crisp. To them, that does not matter 'cause they only have one point five megabits and you can't serve that to them. What we care about is selecting bit rates that maximize the quality we're able to deliver to our end users, but unfortunately, the specifics of how we're planning on tackling that is a whole new talk.
And finally, there is something really mind bending that came out of this research. Imagine you have a clip that is the high complexity piece of content I showed, followed by the low complexity piece of content I showed. If you want to maximize the quality of your renditions, you basically need to delete resolution from your HLS master manifest. In fact, it should never have been there. If if your ABR algorithm is capable of switching between renditions at different resolution seamlessly. There's no reason that it isn't incapable of switching inside a single rendition between resolutions. And if you want to maximize the quality of experience that you're delivering, that's what you're going to have to do. So we're really stoked about tackling some of these problems, especially with HLS and Dash over the next year or two.
Finally, here is a short test clip just to to bring the point home. This is two one megabit encodes of a clip from a trailer for Don't Talk to Irene. On the left is our encode using the convex hull going all the way up to 1080p, and on the right is the Apple bitrate letter as suggested and you can see, hopefully, just how much better the one on the left looks.
This is why it matters.
Thanks.


