
(and 4 other things we learned at Demuxed 2018)
Last week was the annual Demuxed conference. Demuxed is a conference designed by, and for developers working with video. This year for the first time, it ran over 2 days at Bespoke, San Francisco. Here’s the top 5 most interesting things we learned from Demuxed this year.
1: 90% of YouTube viewers don’t care about video quality
Steve Robertson from YouTube dropped arguably the most devastating bombshell of Demuxed 2018.

“Machine Learning for ABR in production” - Steve Robertson @ Demuxed 2018
For a long time YouTube has been running experiments on their viewers to better understand viewer behavior and how best to optimize the video delivery experience for every user. This year Steve told us (with the aid of impressively hand drawn slides) about his most recent experiments.
Recently YouTube has been artificially limiting some streams on the desktop player to 480p - but why? To answer this, we have to look at one of the largest themes of Demuxed 2018: machine learning. YouTube is investigating replacing its adaptive bitrate algorithms with a machine learning based approach which can be retrained on new datasets as users' behavior and network capabilities change.
Adaptive Bitrate (ABR) is one of the core technologies that underlies video streaming on the modern internet. It provides an approach for how playback of video can adapt to changing network conditions. Generally ABR is implemented by measuring the time taken to download the last segment of a video file to calculate the available bandwidth and decide if the client can switch to a higher quality copy of the content. There are a few protocols out there that implement ABR - the most common is HLS, which you can read about here, you might also hear about MPEG-DASH or Smooth Streaming.
Here’s the thing about machine learning - it needs data. Without training data and validation data, you can’t build an algorithm. Training a ML algorithm for ABR is complicated - there isn’t one, simple objective which describes the desired end state. As Steve elaborates in his session, taking the most simple approach you could make the singular objective of the algorithm to be to minimize buffering, this would be trivial to achieve, however, the algorithm would simply always use the lowest quality rendition.
This is where Steve’s experiments start to become valuable - Steve was attempting to create validation data to show that just using a fixed, low-quality resolution had a significant knock on effect to end user engagement, but he was in for a surprise. When Steve locked the player quality to 480p for a subset of views, here’s what he discovered…

“Machine Learning for ABR in production” - Steve Robertson @ Demuxed 2018
Nothing happened, there was no degradation in user engagement by locking the player to 480p. The only measured change was a 3% increase in users manually overriding the quality selection.
Steve goes on to describe how he further extended this experiment by making the quality selector sticky between sessions - so when a user selected 1080p, they would always keep this resolution between viewing sessions, what this revealed was arguably even more interesting. Desktop YouTube users appeared to segment themselves accurately into 2 groups; one who care about quality above 480p (10%), and those who don't (90%). What is really interesting is that that 10% of users actually represent 25% of view time across YouTube.
Why is it that 90% of YouTube users don’t seem to care? Well, that’s tricky. I don’t really think we have enough data to be sure what’s going on, but here’s some thoughts:
- YouTube’s 480p actually looks pretty good, it's certainly watchable, especially on a browser, rather than on a big screen device.
- A lot of YouTube content is not great quality at source; content may be shaky, poorly processed, or repeatedly re-uploaded. Such content may not look perceptively better above 480p.
- A lot of YouTube content relies on voice or commentary to relay information - and in this case, the quality of the audio was unaffected by Steve’s limitations.
- We have limited data on viewport size. Steve mentioned that even when fullscreened on a 1080p or 4k display, the resolution stayed locked, but without what proportion of sessions were fullscreened, its hard to know how actively engaged these users were.
This data makes fairly scary reading for an industry which has traditionally been obsessed with delivering the best quality content whenever possible, however you won’t be catching us at Mux following suit any time soon. We’re committed to delivering better quality, at lower bitrates by leveraging machine learning in our encoding pipeline.
2: The codec war between AOM and MPEG is just beginning
Does anyone else remember the last codec war? Oh that’s right, it's still ongoing with Google favoring the less royalty encumbered VP9 codec, and Netflix still leveraging MPEG’s High Efficiency Video Codec (HEVC). There’s a bigger fight brewing however. A little over 3 years ago, the Alliance for Open Media (AOM) project was founded - this project arose from the VP10 project at Google, Mozilla’s Daala project, and Cisco’s Thor project. The aim of the AOM project is to create royalty free video codecs for use on the internet. AV1 is the first codec they have created.
One of the biggest challenges with HEVC has been its patent situation. There are 3 announced patent pools for HEVC, but even these 3 don’t cover all known patents for the codec.
Known Patent Pools for HEVC - Jan Ozer - Streaming Learning Center
But it seems that MPEG is doubling down on proprietary codecs, as it pushes forward with its replacement for HEVC, Versatile Video Codec (VVC). During Christian Feldmann from Bitmovin’s talk describing the VVC project, he described the new block partitions which would be available, along with the new motion prediction approaches coming to VVC, all targeted to deliver significantly better compression performance over HEVC.
The real question is if MPEG’s VVC can play catch up - as Christian explains, VVC is aiming for a v1 availability somewhere in 2020. AV1 is a long way ahead in the marketplace, not only with commercial commitments from the likes of Netflix, Google, and most recently, Apple, but also in its immediate (if somewhat experimental) availability for use today in the Google Chrome and Mozilla Firefox browsers. Also, there are already commercial AV1 encoders available today from the likes of Bitmovin. By the time VVC is meaningfully available, we’ll probably already by talking about AV2.
Being the first codec to a market usually means you won’t be the most efficient of course. VP9 was released before HEVC, and wasn’t universally adopted outside of Google - it's unclear if we should expect the same with AV1 given the radical adoption by the big names in the industry. However, we should certainly expect higher compression ratios from VVC over AV1 as it has a couple more years of innovation available in its development cycle.
Over the next few years, it’ll be fascinating to watch MPEG closely to understand what platforms VVC is going to be deployed to - there’s going to need to be a pretty big incentive to support yet another codec. Here’s my bet - as an industry we’ll end up supporting both AV1 and VVC, just like we did with HEVC, VP9, AVC, VP8, and many more. As soon as one of the major hardware manufacturers commits to only support one codec, the industry is stuck with both. Of course the process of codec development is also a game of leapfrog - if VVC makes big gains, AV2 will make even bigger gains and so on - the real question is if AOM can compress the codec development process so dramatically that MPEG just can't keep up.
A few other talks touched on the state of play of AV1, which are worth checking out.
- Steve from YouTube revealed that they’re currently delivering around 1Gbps of AV1 encoded content at the edge today, and expect to grow that to 1Tbps over the next month.
- Jean-Baptiste & Ronald from VLC walked us through their new libre and Open Source AV1 decoder, dav1d.
3: Sub-media-segment chunked-transfer is becoming the prefered way to achieve “Low Latency” streaming at scale
Low latency live streaming is one of the hot topics in online video in 2018, with countless vendors demonstrating their new solutions at IBC in Amsterdam last month, and this trend continued into Demuxed. Of course “Low Latency” is an ambiguous term - there’s no consensus on what duration of latency constitutes “Low”. During Will Law’s talk on “Chunky Monkey”, he proposed the following definitions (and use cases, and technologies) for different bands of the Low Latency video delivery spectrum.
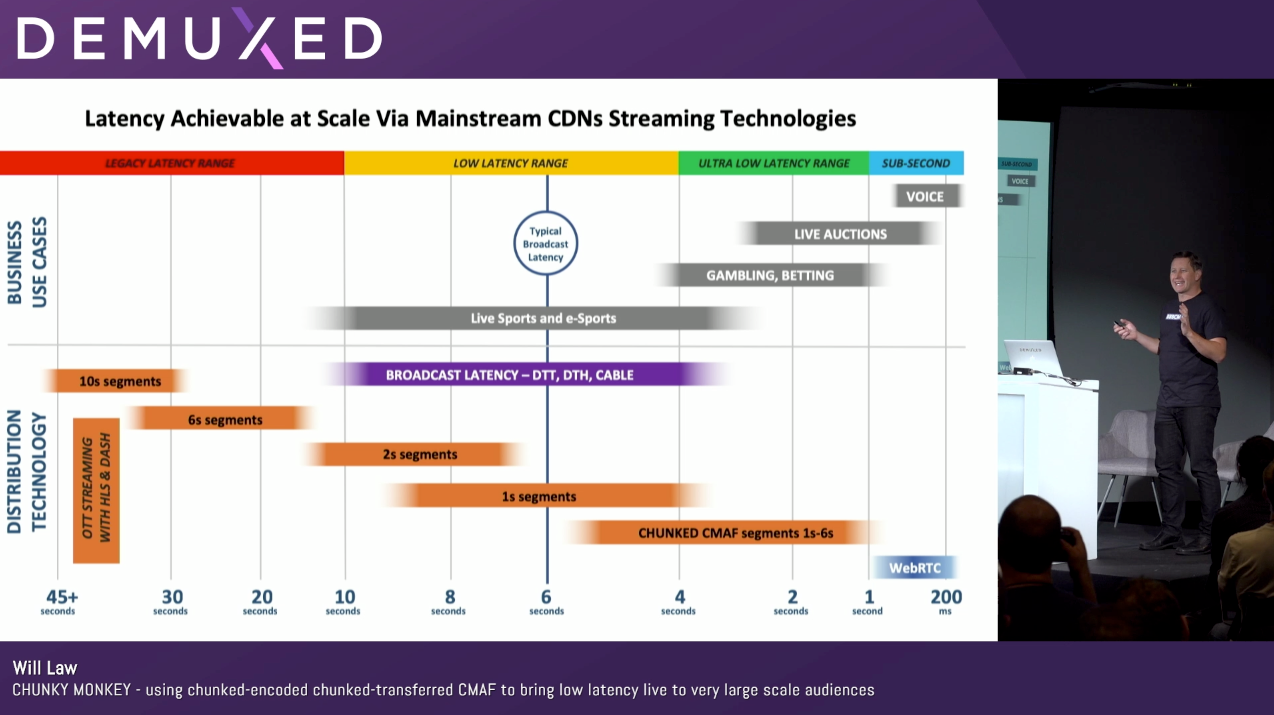
At the cutting edge, low-latency live broadcasting at scale is being approached in one of two ways:
- Leveraging WebRTC to push streams to CDNs, utilising WebRTC relays to allow scale.
- Low Latency Encoding chains, with small segment sizes, and sub-segment fetching via chunked transfer mode.
While WebRTC offers the lowest latency of the current approaches, its limited availability in relay mode among CDNs inherently limits the market penetration of this technology for now. However, chunked transferred segments don’t need any huge changes at the CDN level to start leveraging now.
As described in our HLS article, streaming video on the internet works by downloading small segments of an audio or video file, and appending each of them to a buffer on the machine or device - this is how HLS and MPEG-DASH work. Common Media Application Format (CMAF) is an extension of the ISO BMFF MP4 specification, which defines a common exchange format for the media segments contained within a HLS or DASH manifest. CMAF is in its early days, but is rapidly gaining support across the industry.
Amongst other things, CMAF clarifies that when delivering segment of video, this segment can be constituted of multiple fMP4 fragments. This coupled with chunked transfer mode encoding (a part of HTTP 1.1), allows clients to request a full segment, and receive smaller, progressively sent segments of the content. This means the client can start appending into the decoder buffer sooner than waiting for the full segment to be available, and as such, can dramatically reduce latency.
Beyond needing an encoder that supports chunked transfer outputs, and a CDN that supports this mode of transfer (most already do), fairly minor changes are needed to the player end in order to support this low-latency streaming approach. As Will expanded on in his talk however, this approach introduces new challenges around measuring network performance, as most players rely on segment download performance to measure the available bandwidth.
The really great news is that lots of people have already started working on this approach, and are making forward progress on working towards standardization. In John Bartos’ talk at Demuxed, he described the work ongoing in the HLS.js community to create a standard that can be universally adopted to improve the low latency world for everyone. Mux was proud to be a part of the Low-Latency streaming session at FOMS workshop this year, and looks forward to working with the likes of JWPlayer, Wowza, Akamai, and MistServer to drive standardization and adoption.

LHLS(.js): Why Hls.js is standardizing low-latency streaming
4: Machine Learning for everything is becoming the standard
As I covered at length earlier, YouTube is working on replacing their ABR algorithm with an ML system trained on real world data, but Demuxed 2018 had plenty of other examples of engineers using machine learning to improve streaming video experiences.
As Mux’s very own Ben and Nick explained in their talk “What do do after per-title encoding”, our per-title encoding solution makes use of machine learning to classify your content when you upload it, so we can make the best possible decisions about how we encode your content. Nick and Ben went on to cover some ideas for what comes next after per-title encoding, specifically that we need to start rethinking our traditional approach of trying to maintain a consistent frame size on a particular rendition. The visual complexity of content between scenes rarely stays consistent, so in some cases, we can achieve much more optimal bandwidth usage by not only changing encoding settings between scenes, but also changing the frame size. While this might not strictly be conformant to the HLS specification, it does work very effectively.
One of the most visually impressive uses of machine learning we saw was the combined use of data captured at encode time, VMAF estimations, and a ML based system for re-constructing information lost at encode time. Fabio Sonnati explains this in detail in his session on his “Time Machine" with some very visually impressive demonstrations of re-constructed video frames, as shown below.

5: Big Buck Bunny is traumatizing video developers everywhere
For the uninitiated, Big Buck Bunny is a short movie created by the Blender foundation a little over 10 years ago, and is one of the most popular pieces of content for testing encoders, video players, video platforms etc. because it's distributed under the Creative Commons License Attribution 3.0.
Tragically, the consequences of watching Big Buck Bunny over and over again is starting to have unexpected consequences on the Video Developer community. I won’t spoil the fun, but I highly recommend checking out the video below.
Wrap up
Demuxed 2018 was a great experience full of video, innovation, and socialization. It brought us many fascinating sessions and we can’t wait to see what great content arrives for Demuxed 2019! The recordings will get edited and posted to YouTube soon, but in the meantime, you can relive every session on the Demuxed Twitch page.


