
Philip K. Dick’s classic science-fiction story “Do Androids Dream of Electric Sheep?” confronted mankind's need to differentiate living things and machines. While it’s currently easy for us to make this distinction in real-life, doing so on the Internet has become increasingly difficult. This problem extends to consumption of online video by web crawlers and scrapers.
Web crawlers and scrapers are a class of software designed to follow links in web content and scan large sections of the Internet. Crawlers are often used to extract metadata from web content to support useful activities like web searches; the search engines at Google, Facebook, and Microsoft rely on data gathered by proprietary crawlers. Scrapers are less benign, often downloading entire web pages and their resources (videos, images, CSS, etc).
I’ve learned that crawlers & scrapers can have a broad and complex impact on video playback metrics. This blog post describes the events that led to my discovery that crawlers play web videos, our techniques for identifying crawlers, and some of the interesting ways they can affect video playback metrics.
Why is Firefox 38 broken?
Mux began work on an anomaly detection system in the summer of 2016. Our goal was to automatically find anomalies in the error rates for individual video titles and across entire customer sites (properties).
Early testing yielded a large number of alerts that appeared to be false-positives. Many of these alerts were triggered for views with ancient browser versions, such as Firefox 38, which was over one year old at the time. Other oddities included the time of day and country where the videos were being viewed relative to the target audience of the content.
The false positives in error-rate alerts were more than just a curiosity in the data; they were preventing us from releasing our alerting feature to a wider audience.
"Instead of looking for the answers the data provides, look for the questions it generates" (Bill Pardi, Microsoft Design Blog)
If we had taken the data at face value, we might have concluded there was a serious defect in Firefox 38 and/or the HTML5 video player on the Mux customer sites we used to test this feature. We wanted to believe that all of our video views were generated by people. However, instincts developed from years of experience with online video told us that these errors were not legitimate.
We had a theory that these views were coming from crawlers or scrapers.
Web crawlers and scrapers often use browser user-agent strings with software versions that that lag behind the versions of software they're faking. Browsers that automatically apply updates have become the norm, so it was very strange to see such a large number of views from software more than a year out of date. We had a theory that these views were coming from crawlers or scrapers.
Why Would a Crawler Play Video?
“It is the basic condition of life, to be required to violate your own identity. At some time, every creature which lives must do so. It is the ultimate shadow, the defeat of creation; this is the curse at work, the curse that feeds on all life. Everywhere in the universe.”(Philip K. Dick, “Do Androids Dream of Electric Sheep?”)
An increasing number of websites rely on JavaScript for navigation. W3Techs reported on June 12, 2017 that 94.5% of all websites surveyed use JavaScript, sampled from the top 10 million websites tracked by Alexa. This isn't terribly surprising, but it helps emphasize the importance of having a JavaScript engine when crawling or scraping a website.
This has led to simple text scrapers being abandoned in favor of more complicated crawlers that execute JavaScript on each page they crawl. Such crawlers often depend on a headless browser like PhantomJS and the Chromium Embedded Framework (CEF). There are comprehensive lists of browser engines and projects that use them.
How do these headless browser engines handle video content in the pages they crawl?
I searched the PhantomJS mailing list for video-related questions and was not disappointed. The official word is that audio & video are not supported by PhantomJS. However, there was no description of what happens, if anything, when PhantomJS encounters video content.
It was time to write a crawler.
Pics Or It Didn't Happen
I needed a repeatable demonstration of a PhantomJS-based client that triggers loading of video elements in an HTML page. My sanity demanded it.
The following code uses the Horseman project to access page content retrieved with PhantomJS. For those playing along at home, install Horseman & PhantomJS and run the following script using Node:
Next, I accessed the Mux dashboard to find the video playback attempts initiated by PhantomJS as part of my tests. The following screenshot shows the details of the video view I generated. The error-message No compatible source was found for this media makes sense considering that the PhantomJS engine does not have the ability to decode audio or video.
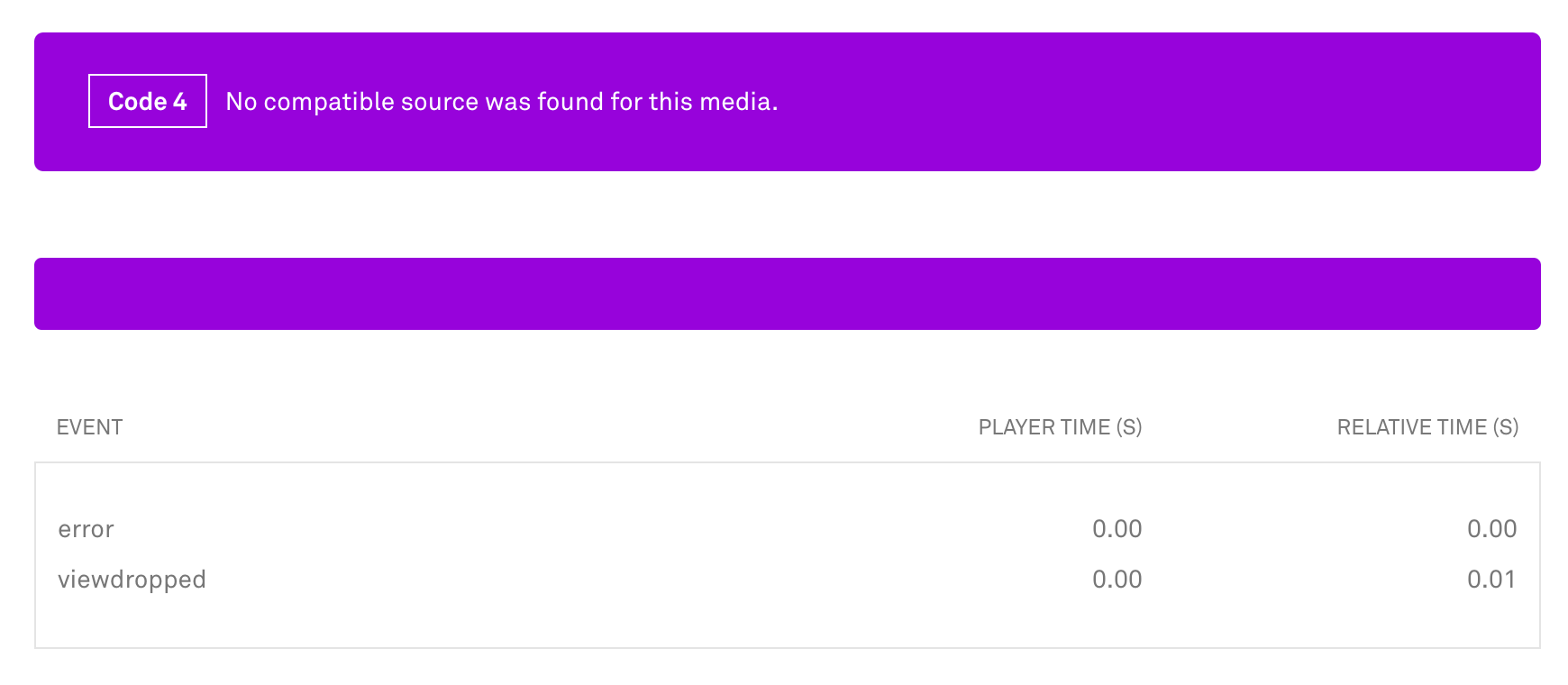
This was a significant achievement. I'd proven that crawlers using PhantomJS trigger the creation of video-views in Mux, and that those views will likely register as an error. This is extremely problematic because a wave of crawlers accessing the website of one of our customers could trigger a flood of error-views.
We needed a way of identifying crawlers and excluding them from our metrics.
Identifying and Excluding Crawlers
“An android,” he said, “doesn’t care what happens to another android. That’s one of the indications we look for."“Then,” Miss Luft said, “you must be an android.”(Philip K. Dick, “Do Androids Dream of Electric Sheep”)
Prior to publicly releasing Mux's error-rate alerts feature, we began examining video-view attributes to determine if they come from a crawler. A few of the attributes we look at include:
- Browser User-Agent strings of known crawlers
- IP-address blacklists of known crawlers
- Data Center IP-address ranges where crawlers are known to lurk
These checks help us flag crawler views from aggregate metrics calculated and displayed in Mux analytics.
Let's examine some of the impacts we've discovered while analyzing our raw video view data.
Video Views from Data Centers
The following charts highlight differences between data center (DC) and non-data center (non-DC) views for several of our key customer properties. The customer property identifiers have been changed in the interest of anonymity, and are consistent for each of the charts presented here.
First, the error-rate for DC views is significantly higher than non-DC views. Views with errors like the one that I generated using PhantomJS would show up in the error rate calculations here:
Similarly, the Time-To-First-Frame (TTFF) for DC views is typically higher than those for non-DC views. This measurement represents the number of milliseconds from when playback is initiated, to when a video frame is first shown:
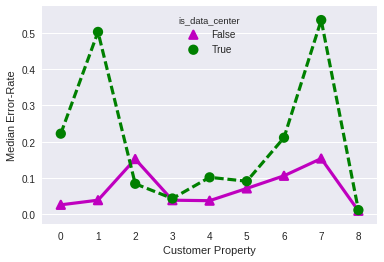
Things get a little weird when looking at the Exit-Before-Video-Start (EBVS) metric:
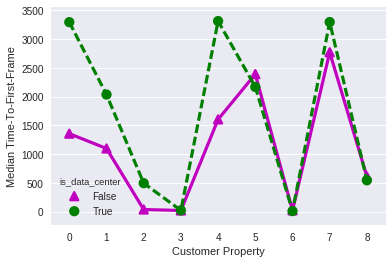
The EBVS metric is extremely high for DC views on Property 8, whereas it's pretty consistent across DC and non-DC views for nearly all other properties. What's going on here?
Most crawlers do not fully render the contents of IFrames.
It turns out that Property 8 has a video player embedded in an IFrame. Most crawlers do not fully render the contents of IFrames. The crawler retrieves the IFrame source and performs just enough processing to trigger the creation of a video view in Mux, but renders the IFrame in such a way that video playback is not initiated, leading to an Exit-Before-Video-Start condition. It's also worth noting that Property 8 is relatively unaffected in the error-rate and TTFF metrics for DC and non-DC views.
A possible conclusion is that placing video content in an IFrame is an effective method of avoiding video-view errors triggered by crawlers.
Crawlers from Planet Facebook
Crawlers often run in environments with CPU and network throughput constraints that are self-imposed. This is mutually beneficial to the crawler operator and the site being crawled. It enables the crawler to simultaneously access multiple sites while not overwhelming the site network and server resources.
However, these constraints have the potential to distort performance metrics for video playback if the crawler happens to trigger the loading of an embedded video. Network throughput limits could lead to ridiculously poor measurements for key metrics like TTFF.
I examined the data-center TTFF metrics for one of our customers who produces a lot of videos shared on social media. For view data spanning a one-week period, I aggregated views by data center, calculated the 50th-percentile values for each data center, and then sorted the results by TTFF in descending order.
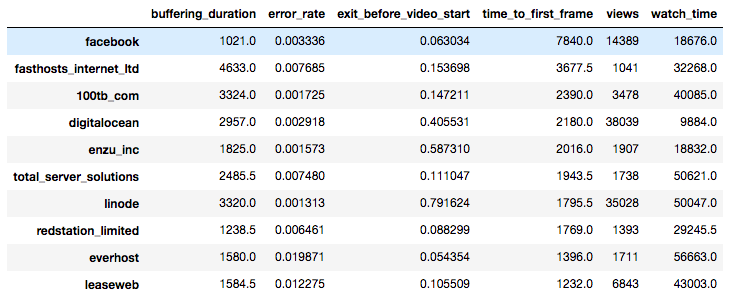
The worst performing set of data center IP ranges belonged to Facebook.
We also record the Network Autonomous System Number (ASN) used to identify the router from which each video view originates. I performed a similar calculation as before, except this time grouping the views by ASN:
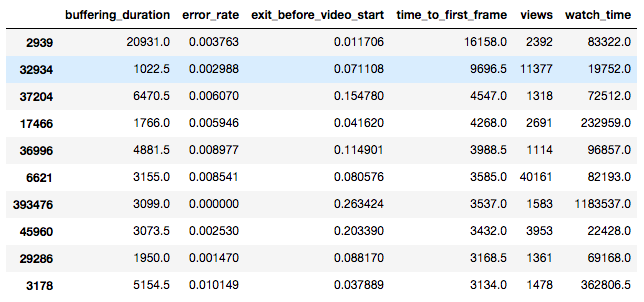
The worst performing ASN belongs to the State of South Carolina (2939), which is kind of surprising. The second worst performing ASN belongs to Facebook (32934). Keep in mind that the ASN table includes network routers that carry DC and non-DC traffic.
Crawlers from legitimate & well-meaning organizations like Facebook have the potential to trigger video playback and influence performance metrics unless steps are taken to exclude them.
Facebook's crawler documentation states: "Facebot is Facebook's web crawling robot that helps improve advertising performance. Facebot is designed to be polite."
Analysis of the user-agent strings used in requests shows that the Facebot user-agent pattern was used in only 0.3% of all requests from the Facebook ASN:

The remaining user-agent strings from the Facebook ASN reflect a wide assortment of mobile and desktop devices and browsers. Some of these requests are certainly valid video views from people using devices on the Facebook network; however, for the median TTFF performance to be this poor, the bulk of the requests are probably from resource-limited crawlers.
Note that the crawler is actually downloading video content that is non-trivial in size, and surely slows down the crawler because of the network bandwidth limits that it's operating under. This is an undesirable outcome for everyone involved.
It's understandable that Facebook has crawlers in addition to the publicly documented Facebot. I'd like for Facebook to state more plainly that the Facebot user-agent string alone is not enough to identify Facebook crawler requests.
Conclusion
Crawlers are a valuable tool for discovering and indexing content on the ever-changing Internet, but we've demonstrated that their interactions with web videos can create a false impression of playback errors and slow media delivery.
Reflecting on the process of building our crawler-detection system reminded me of how Google's development of Google Earth led to the accidental discovery of magnetoreception in cows. Satellite imagery of large cow herds around the world revealed that cows naturally arrange themselves in a North-South configuration. This was certainly not something that Google set out to find when building Google Earth, but they remained open to new insights that would reveal themselves through tools they built. It’s impossible to anticipate all the ways your product might be used.
At Mux we build tools that make delivering video easier than ever. We've made interesting discoveries along the way, leading to improvements in our product. Some of these discoveries have the potential to improve the online video experience for a much larger audience too.
We invite you to start a free trial of Mux today to learn how you can improve the online video experience for your audiences!
“Banksy NYC, Coney Island, Robot” by Scott Lynch is licensed under CC BY-SA 2.0


