
Hello and welcome to this Mux blog miniseries about some of Mux’s usage of the Envoy networking proxy within our Kubernetes clusters. We’ll talk a bit about the decisions that led us to our current use of Envoy and how we incorporated it into our systems. In a later blog post, I also hope to cover some of the challenges we’ve encountered with Envoy in the course of adopting it. I sincerely hope the information provided here will be interesting and useful to those of you who consume it. Let’s get started.
Why are you using Envoy?
Within Mux’s video product, the vast majority of our interservice traffic is carried out via gRPC, which runs on top of long-lived HTTP2 connections. Additionally, our services are run on top of Kubernetes. This leads to some fairly well-documented issues with load balancing wherein long-lived connections are generally kept alive for an extended period of time and not properly round-robinned around the set of available Pods. Over time, this can lead to uneven load and an inability to horizontally scale effectively. In practice, this meant we would sometimes receive alerts related to the performance of a particular overloaded Pod, which our oncalls would need to resolve with a manual restart. This situation was obviously not desirable or sustainable, so we began to seek out some solutions.
We considered several different approaches to this problem, which I would generally group into 3 different categories: client-based, sidecar/proxy-based, and full service-mesh–based. I would say these roughly scale up from left to right in terms of the overall complexity and volume of what you’re introducing. Let’s take a look at what they entail.
Client-based
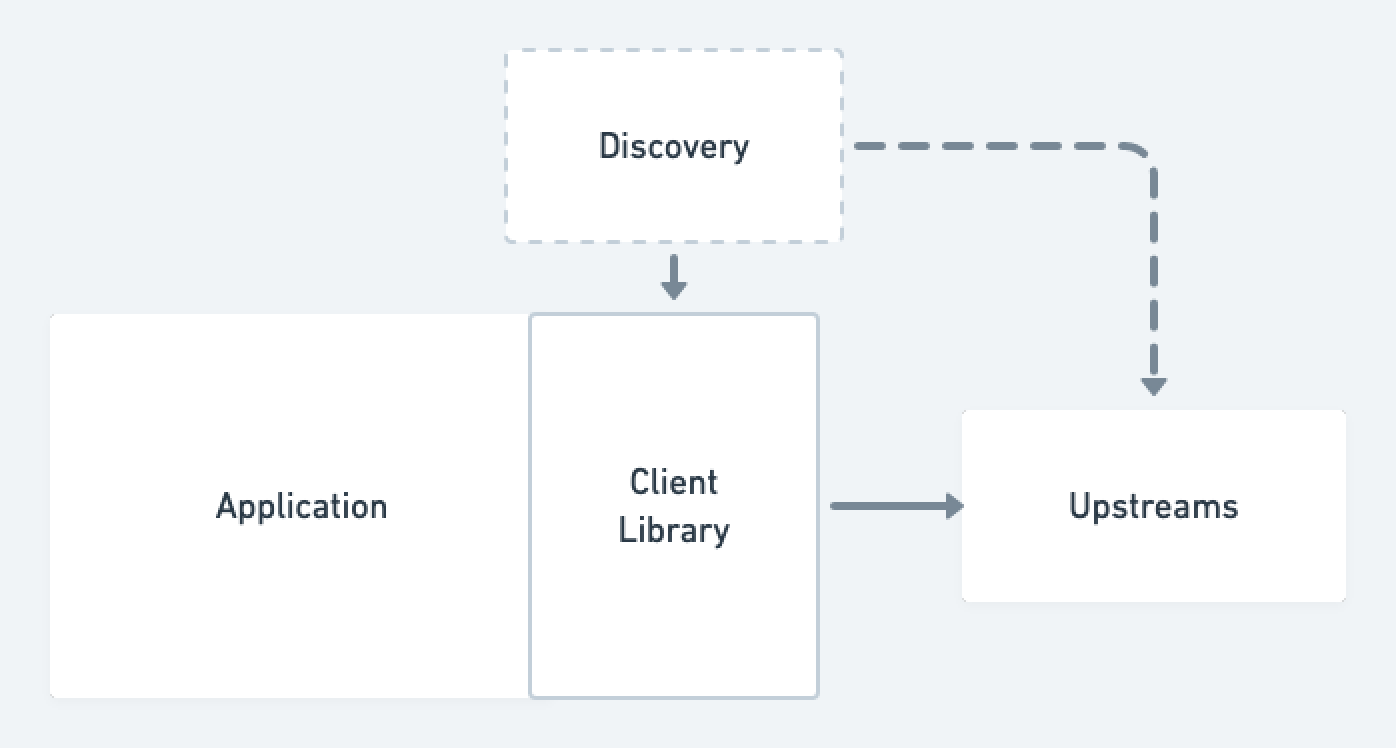
Client-based strategies were those that included making modifications or taking advantage of features within our gRPC client libraries to properly handle load balancing. In particular, most gRPC client libraries possess some capabilities to this effect (an example in Go), and taking advantage of these features at the client level has the benefit of not introducing much in the way of dependencies or points of failure external to the service itself. We ended up not choosing a client-based approach for several reasons. First, these approaches were not language agnostic and required bespoke setup within the libraries of every programming language that we use to write a gRPC service. While we are primarily a Golang video streaming shop within Mux, we are not entirely so. Second, most of the client-based approaches were in various, somewhat early stages of development (the linked official Go gGRPC balancer package is listed as experimental), and we didn’t necessarily feel comfortable betting the farm of something as critical as networking on somewhat unproven tech. Finally, client-based approaches come with myriad standardization challenges across distributed systems, and they require ensuring version and functional compatibility across multiple different services in multiple different languages. Any upgrades that are performed must be done by rolling applications directly, which is more invasive than upgrading an external service.
Sidecar/Proxy-based

The second category of solutions we considered were those that involved setting up some network proxy to run on our infrastructure without involving a full service-mesh. Some potential network proxy candidates that were on the table were HAProxy, Nginx, and—as you may have guessed—Envoy. In terms of where the chosen proxy was placed within our overall infrastructure, we considered options of running it as a standalone deployment, a per node daemonset, and a per Pod sidecar container. As the title of this post gives away, we did end up choosing this category to solve our problems; we can circle back to the why after we see what didn’t work out for us with a full service-mesh.
Full service-mesh
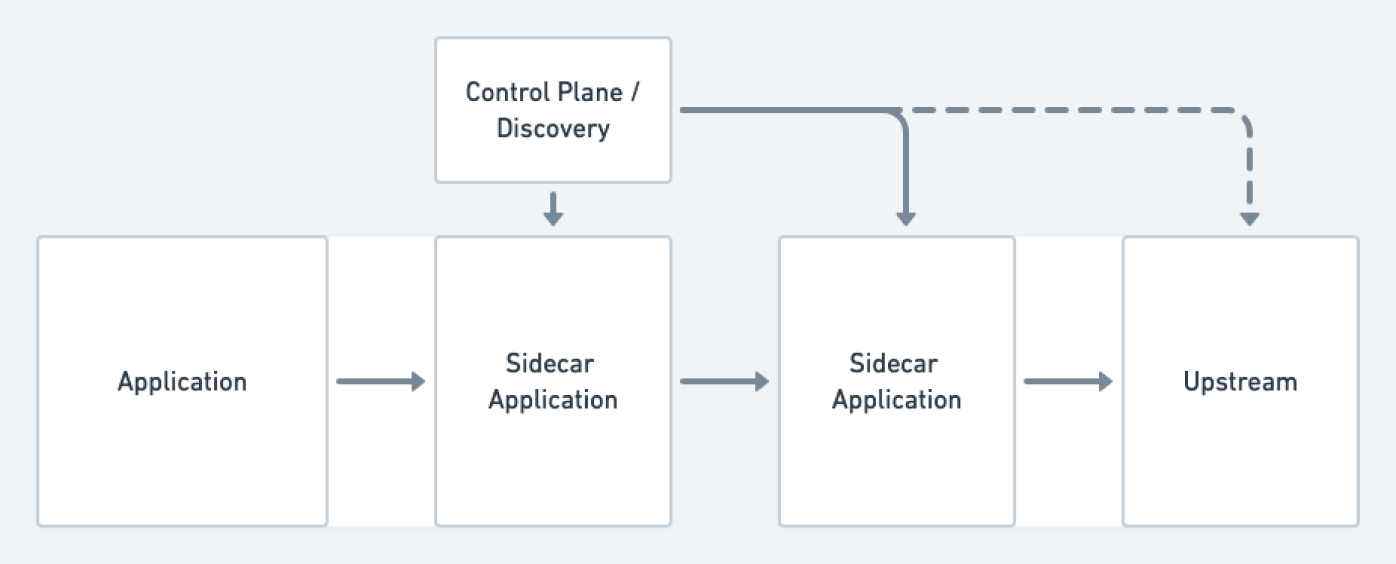
The full service-mesh solutions generally involve a combination of network-level components (often sidecar proxies such as Envoy or Linkerd2-Proxy) alongside some kind of management layer that serves as a configuration and control plane running over the network-level components. Some options we considered were Istio, Linkerd, Maesh, and Consul Connect. Ultimately, we ended up dismissing all of these options for several different reasons. In some of the cases, the perceived complexity of the technology and overall cost to operate were considered to be too high. Additionally, several of these solutions were incompatible with the versions of some of our older Kubernetes clusters (1.8, 1.12) that we were running at the time of consideration, and sustainable strategies for upgrading these clusters were still some ways away.
Revisiting the second class of solutions, we can see that they meet our needs of being language agnostic, while not introducing too much overhead to manage or relying on features not available in our version of Kubernetes. When it came to picking a particular option within that class, we decided to go with Envoy primarily due to our already making use of it at our edges for network ingress, its reputation for performance, and its rich feature set that we could potentially take advantage of.
How we set up Envoy
As mentioned above, we had the option to deploy Envoy as a standalone Kubernetes deployment, a daemonset, or a sidecar container. In a deployment setup, we would create a pool of Envoy instances that would field requests for all services that wanted to make gRPC requests. However, this approach has the potential to impact network performance by putting an additional hop into all of your requests, and additionally needs to be carefully scaled up alongside any other autoscaling that may be happening within your cluster to ensure you have sufficient proxying capacity to meet demand. In a daemonset approach, you avoid the potential of the additional network hop by ensuring that every host that runs Pods that make gRPC requests have a running Envoy Pod that proxies all of their traffic. This approach runs several risks, however, as the loss of this single daemonset Pod will mean that all outbound gRPC requests on that host will fail. Additionally, horizontal scaling becomes a challenge, as fluctuating network load on the host needs to be handled by only a single Pod.
Given these issues, we chose the final option of a sidecar container. This approach has the downside of increasing the size and profile of every Pod by placing an additional full networking container alongside the server you wish to proxy for. This can be potentially inefficient, but as long as this sidecar container is appropriately sized, you don’t really end up underutilizing it. Additionally, this setup has the benefit of automatically letting your network proxying capacity scale alongside any automatic scaling of services. A new Pod scaling up will automatically scale up the required network proxy right alongside it.
To properly enable this sidecar approach, we took advantage of the fact that we declare most of our Kubernetes setup in Starlark-based declarations that are very similar to what’s enabled by Isopod. This lets us define Envoy sidecar injection as a Starlark library that can easily be enabled in our services with an import and some method calls. In practice, this is what a simplified version looks like:
envoy = package(“./path/to/envoy/pkg”)
def k8s_deployment():
d = deployment(“my-application”)
# skipping over other standard deployment configuration...
if envoy_is_enabled:
envoy.configure_sidecar(d)
return d
def envoy_config():
if envoy_is_enabled:
return envoy.config_map(“my-application”, “my-upstream”)And that’s all there is to it. If we toggle the boolean, Envoy will be enabled and injected as a working sidecar for Pods in that deployment, and it can be disabled just as easily. Running the code listed above produces a Kubernetes deployment for the application with a running Envoy sidecar and configures the application to point to the Envoy sidecar via overwriting container flags and/or environment variables. Within the service application code, we generally wait to fully start the service until we detect the Envoy sidecar is up and ready by probing its /ready endpoint. The code above will also produce a ConfigMap, which is mounted and used as a configuration file for the running Envoy sidecar. This configuration sets up Envoy to properly forward gRPC traffic over HTTP2 for any number of upstream applications that the primary service communicates with.
Similar sidecar injection approaches are probably feasible using something like Helm or other YAML templating solutions. In our case, our library appends Envoy as a sidecar container to the primary service Pod and appends a flag or environment variable to the primary container to configure it to point at the localhost address of the Envoy sidecar for gRPC networking. The Envoy sidecar is configured via a mounted ConfigMap that specifies which upstreams it’s personally responsible for proxying to. Service discovery to determine which instances are part of an upstream is carried out over DNS. We simply create a headless Kubernetes service for the upstream we want to Discover and rely on the fact that Kuberentes and Kube-DNS will create a DNS entry that contains the instances in that service. Envoy only needs to watch this DNS entry. We may one day switch to more of of an xDS-based system , but for now, relatively static configuration via ConfigMaps is perfectly sufficient for our use cases. By starting with a straightforward and more static configuration setup (that still meets our needs), we can more easily grow to understand Envoy in all of its complicated glory without needing to pull in the whole feature set. This is a similar line of reasoning to why we held off on an entire service-mesh solution as well.
Conclusion
Since getting this setup running and rolled out, we no longer see any of the aforementioned issues with gRPC load balancing; we get some very solid networking metrics for free via Envoy; and we’ve been able to find several other valuable use cases for Envoy proxy injection outside of our gRPC services. We’ve had few to no issues with Envoy itself, outside of some gotchas and learnings that we discovered in the course of the initial setup and rollout, which I hope to cover in a later blog post. I’ve personally enjoyed the chance to get to work directly with Envoy, which is a very powerful (and complicated) piece of software.


