
There’s a common anti-pattern in engineering orgs: one team comes up with a solution, then another team builds their own despite how similar the needs are. Rinse and repeat a few times. Eventually, you get to a point where you need to address the tech debt and build something that works for everyone. In this post, I’ll cover our recent experience solving this issue while unifying our signing keys. We’ll go over the problem, dive into the technical design, and identify how to leverage this work for future initiatives.
How Mux uses signing keys
Mux products use signing keys, which consist of RSA public/private key pairs, to cryptographically sign and validate JSON Web Tokens (JWT). JWTs are a common mechanism for authorizing client environments like browsers and user-facing applications to interact with your backend service. API keys work great for authorization from secure servers, but since you wouldn’t want to expose those keys directly in client code, JWTs can be a useful alternative.
Our products use signed JWTs in several ways. For instance, if you want to limit your live stream to paying subscribers only, you can use Mux’s signed playback URLs to ensure that your stream can only be accessed from a certain domain. For Mux, it’s important to preserve low latency during this process. Any delays with URL validation, and ultimately in video playback, are going to be felt by viewers.
Previously, different Mux products were built with separate signing key implementations. This meant that a Mux Data signing key couldn’t be used to sign a Mux Video JWT, and vice versa. Keys were kept in two separate data stores, which were accessible through two separate APIs. As Mux built more products that required signing keys, this approach became undesirable in terms of customer experience (separating keys per-product grew confusing) and engineering maintenance.
There can be only one
To address these issues, we decided to unify all of our signing keys under one service. This service would be responsible for key reads/writes and could ideally be extended to perform signature validation. However, this newly unified service would become part of the critical path for multiple products. If not designed carefully, it had the potential to introduce a single point of failure.
Given our multi-product use case, we had several hard requirements:
- High availability and low latency (<20 ms)
- Ability to serve a highly distributed read-heavy workload
- Continued availability during a regional or cloud outage (e.g., AWS going down could not impact our ability to serve GCP regions)
Easy peasy, except…
The challenge with unification was the distributed nature of the service’s consumers. We operate Kubernetes clusters in AWS and GCP, spread across regions in the US and Europe. Delivering this data with milliseconds of latency was going to require a system with entry points spread across these locations.
What we considered
We knew we needed a data replication model that could span clouds and regions. We briefly considered writing an API backed by an origin database (e.g., Postgres), paired with edge CDNs that could cache keys (and possibly perform edge validation) closer to consumers. Our Data team already performed edge validation of signing keys with Cloudflare workers, so we had prior experience we could leverage. We could implement a data replication model where CDNs would pull keys from the origin when needed, or one where the origin would push any newly written keys to all CDNs immediately. However, an immediate limitation was that Fastly dictionaries have a limit of 1000 keys, making the second option a nonstarter.
The pros: By involving CDNs as key-value stores for edge computing, we could perform validation at the edge with extremely low latency. We would have one central database to manage, which might mean less operational burden than a distributed database. With such read-heavy access patterns, containing writes to one regional source of truth could simplify things.
The cons: We would be responsible for keeping data available, consistent, and replicated at the CDNs. This model also introduced a single point of failure for multiple systems and left us open to denial-of-service (DOS) attacks. Adding any active-active or active-passive strategy to mitigate this risk would quickly introduce more complexity.
Introducing a distributed database
A distributed database was a much better fit for our use case. Using something like CockroachDB (CRDB), we could ensure data was local to every Kubernetes cluster instead of being gated behind an external interface. Here are some of the features we valued:
- Built-in replication and consistency
- Horizontal scalability by design
- SQL support
- Multi-zone, region, and cloud capabilities
- Online upgrades
Nothing in life is free
Not everything was perfect, and there were some disadvantages to using such a distributed database:
- More operational overhead
- Networking complexity and debugging difficulty
- Secret, certificate, and RBAC management
- More configuration to keep in sync
However, our biggest concern was that the database needed to be multi-cloud. Although we had experience with multi-region CRDB, this would be the first multi-cloud database at Mux. Because distributed databases require inter-node communication to achieve consensus, high latency between any two nodes could severely impact the transaction latency. We didn’t have any prior art to lean on for evidence of network feasibility.
Despite the unknown factor of cross-cloud communication, using a distributed database made the most sense. If we succeeded with proving this out, we could proceed with more confidence deploying future cross-cloud databases. Mux is committed to being a multi-cloud platform, so this would be a strategic investment.
Our final design
The final architecture introduced a Go microservice into three of our AWS/GCP Kubernetes clusters where signing keys were needed. Each microservice would front 3 colocated CRDB nodes to guarantee local availability and quorum during maintenance and zone failure. All CRDB nodes would join a single multi-cloud CRDB cluster. As a result, every included Kubernetes cluster would contain an instance of the microservice and 3 CRDB nodes.
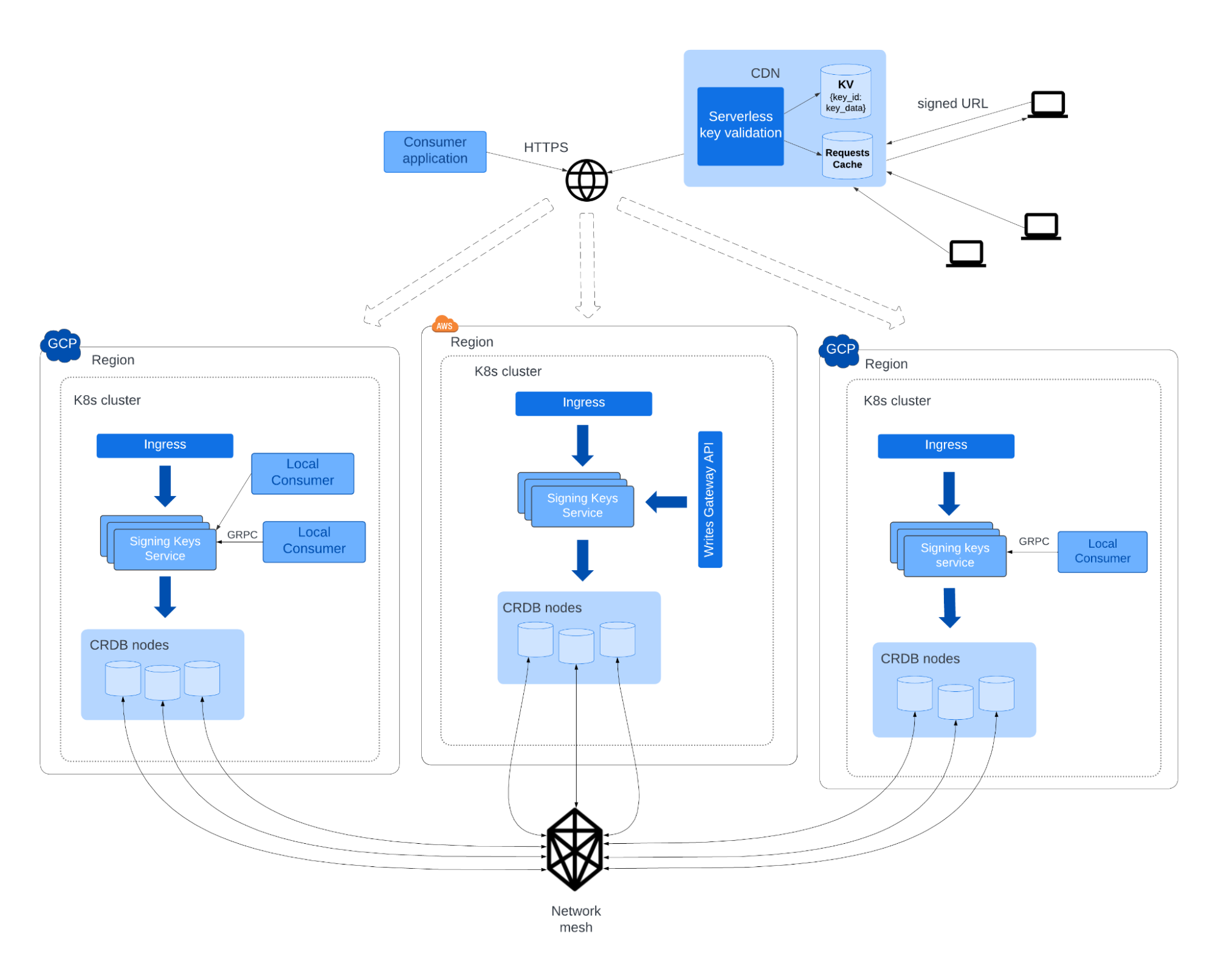
Cluster topology
CockroachDB can be configured with several multi-regional topology patterns. Given the critical nature of the service, we needed to stay up through regional outages (looking at you, AWS us-east-1) and network disruptions. So we set our database survival goal to REGIONAL, meaning it could remain available even if a whole region failed. This was the most resilient option, but it came at the cost of higher write latencies. For us, this was acceptable because we intended the database to be read-heavy, a luxury not every service has.
A signing key could be written anywhere and read anywhere. Since we could not assume keys written to one region would mainly be read from the same region, we used CockroachDB’s GLOBAL table locality, which could serve low-latency non-stale reads from every region. Again, the tradeoff here was higher write latencies. CockroachDB achieves consistent replication and non-stale reads by setting write timestamps in the future and waiting until then to unblock, while quorum/replication is achieved concurrently. As you can imagine, optimizing write latency is the hard part here. For information on how that works, see this excellent blog post.
Let’s build this thing
Mux was no stranger to deploying CockroachDB clusters across multiple regions. However, deploying a cluster across multiple clouds was uncharted territory. For this approach to work, we had to prove we could achieve acceptable networking latencies between AWS and GCP.
CockroachDB nodes require a full network mesh. To accomplish this, the team deployed CockroachDB in Kubernetes StatefulSets hosted on dedicated AWS/GCP nodes. Static IPs were assigned to these instances, and we punched holes in each node’s firewall to allow traffic from all other node IPs. This solution, though tedious to set up, worked for our purposes. We recognized that sending traffic over the public internet can present an unknown in terms of sudden congestion and spikes. However, given resource constraints, we decided to not use a private networking solution here. The risk was significantly lower with the public route because our use of global tables meant reads could always be served by local nodes. Initial staging tests established an acceptable performance baseline. Writes were quite slow at 1 s, but reads were averaging 2 ms at 160 rps.
The moment of truth, aka migration time
After our cluster was set up, we had to migrate all signing keys from their old data store to the new database. We set up our gateway API to dual write keys to the old and new systems to keep data in sync during the migration period. After importing all existing keys into the new CRDB and performing verification, we routed consumer traffic to the new service over a few days with a percentage-based rollout. All in all, we took a week to migrate all data and clients to the new service.
How did it turn out?
Overall, the process went smoothly, and our multi-cloud CRDB cluster has proven to be quite stable. Here is a snapshot of our prod network latency between nodes. As expected, cross-cloud latency is the highest, but still within an acceptable range.
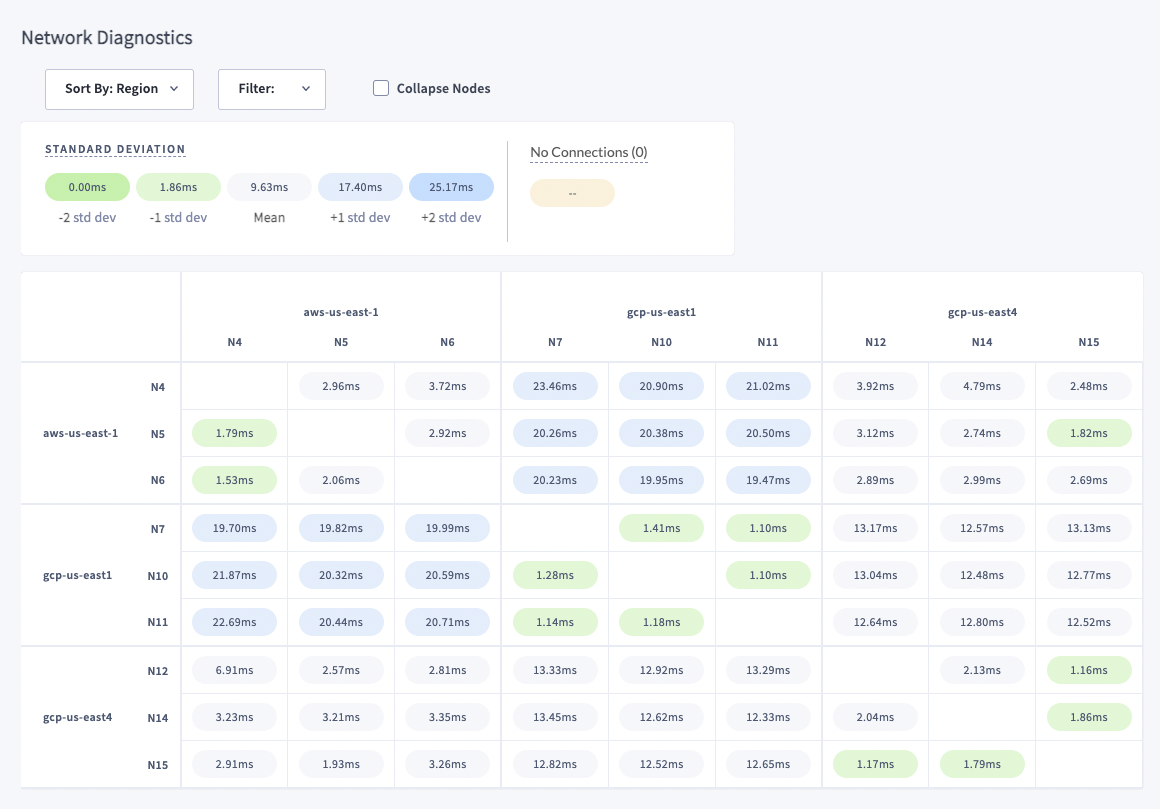
Instrumenting the cluster was fairly easy because Mux had already developed a robust monitoring and observability stack. CockroachDB also provides a detailed console UI and easy Prometheus integration.
Most importantly, all teams are now using a unified signing keys service that is easily scaled and maintained 🥳.
What’s next
Successfully shipping a service to prod on a cross-cloud database has significant implications for future engineering efforts. In addition to proof of network feasibility, we now have a CRDB cluster that can host other (currently) single-region databases. This opens up possibilities: For any migrated database, a write committed in AWS us-east-1 can be made immediately available in GCP regions. The team is already capitalizing on this by moving feature flags and global organization data into our new CRDB cluster. Moving forward, we’re excited to keep pushing regional and cloud boundaries in new ways!


