
Mux just returned from an exciting week at the 35th International Conference on Machine Learning (ICML). This was our first year attending, and it was great to spend an immersive week in talks and workshops to learn about the latest in machine learning.
Compared to other machine learning conferences, ICML is much more focused on the latest cutting-edge research across all domains of machine learning.
Growth of ICML
The popularity of ICML has grown considerably since it first began in 1980. In the past ten years, the number of submissions has grown approximately five-fold from 500 to an astounding 2,500 this year.
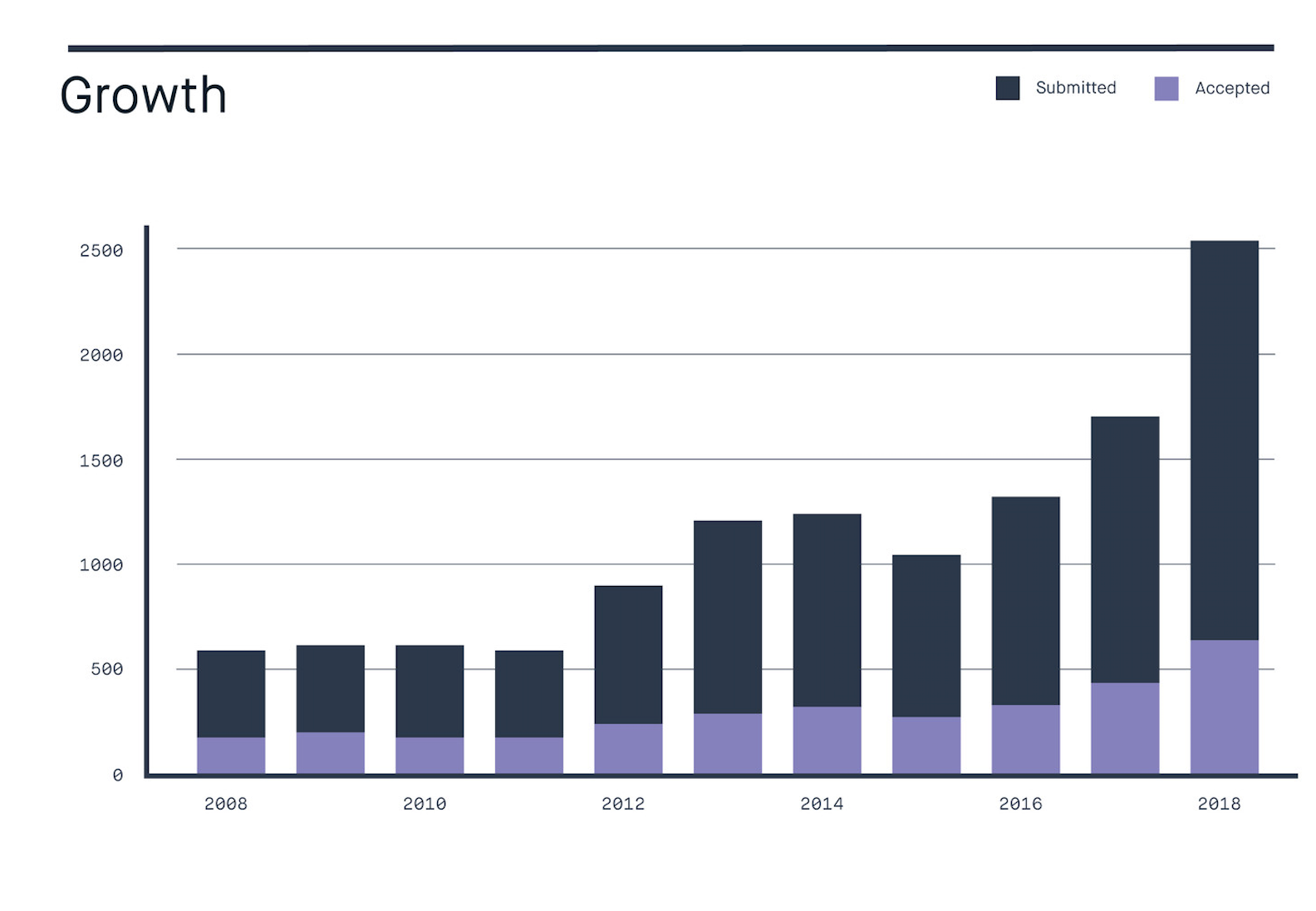
Source: Peltarion
Out of those submissions, ICML accepted 631 papers. The majority of accepted papers came from who you'd expect: the powerhouse tech companies and prestigious universities. Microsoft had 26 accepted papers; Facebook AI Research (FAIR) managed 19 accepted papers; Amazon, Tencent, and Uber each managed around 10 papers. Apple lagged behind the rest with a mere 3 papers.
Much has been said about Alphabet's lead in machine learning, but it becomes readily apparent simply from comparing the publication counts. There were 30 papers by DeepMind alone; meanwhile, Google AI had an astounding 52 papers.
In other words, Alphabet had more papers at ICML than Facebook, Microsoft, Apple, Amazon, Tencent, and Uber combined.
Talks and Submissions
Unlike some business-focused AI conferences, like ODSC or O'Reilly for example, the content at ICML is more academically centered and seemed to have two main themes:
- How can we beat the previous state-of-the-art in computer vision, natural language, reinforcement learning, etc.?
- How can we achieve close to state-of-the-art results while dramatically improving performance?
For recurrent and convolutional networks, more of the talks seemed to be centered around performance and optimizations. A few excellent papers on optimizing training for deep networks include Spotlight, which uses reinforcement learning to optimize device placement, and another paper on optimizing DNNs through overparameterization.
Improving the efficiencies of networks was also the subject of Max Welling's excellent keynote talk (and my favorite of the three).
Many of the optimization talks given were related to reinforcement learning, which continues to have serious hurdles when it comes to convergence speeds.

Earlier this year, Alex Irpan wrote an excellent blog post detailing many of the current issues with deep reinforcement learning, such as huge learning times or unstable convergence. So, it's unsurprising that reinforcement learning was a main focus of the conference.
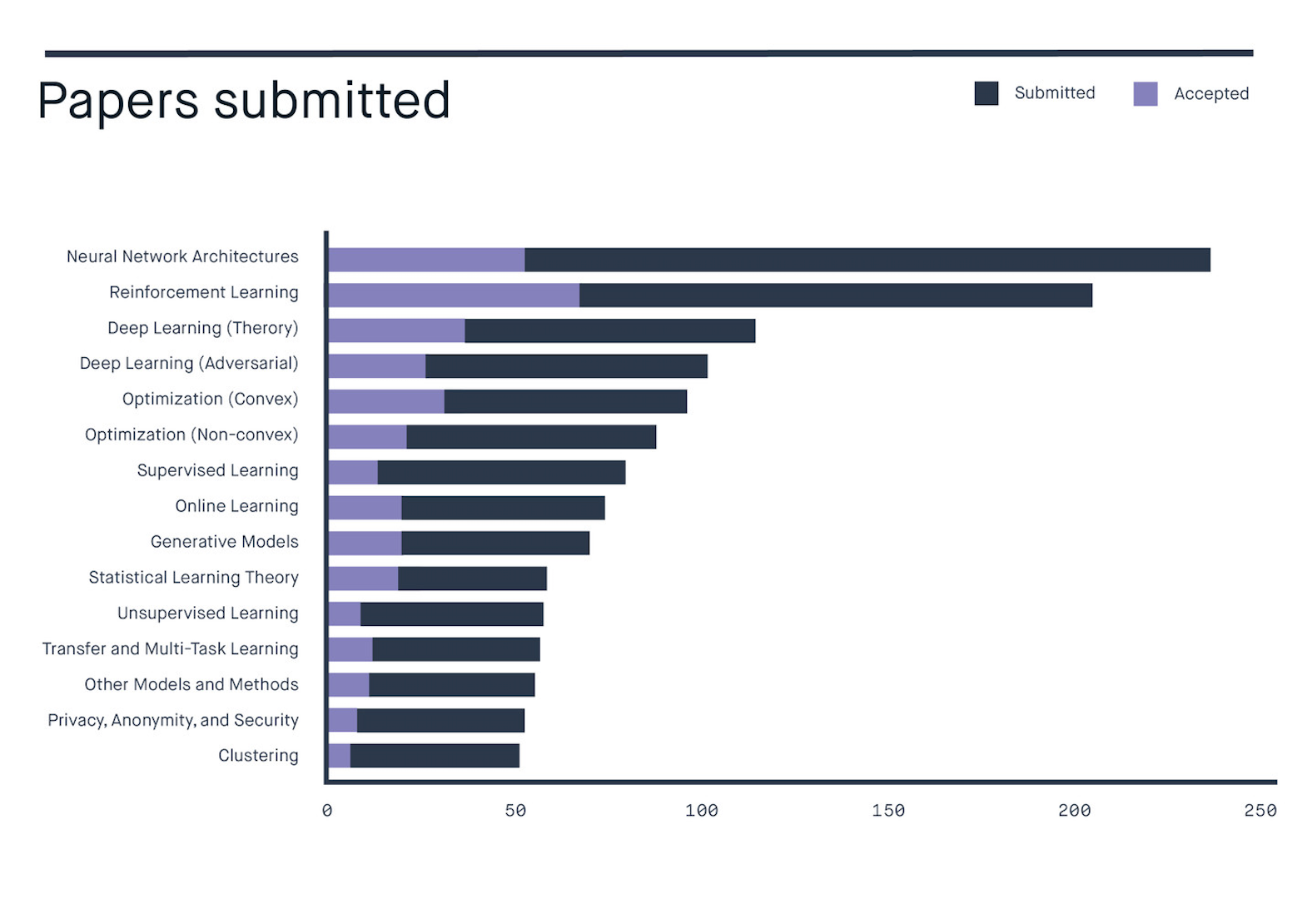
Source: Peltarion
RL dominated the sessions, along with neural network architectures, which was less focused on a specific domain. A few of our favorite picks from the reinforcement learning sessions are:
Concurrent Reinforcement Learning, which showed a significant speedup in training Cartpole by running concurrent simulations and sharing information periodically
Transfer Learning with RL, a DeepMind paper that details a transfer framework for changing the reward function in an environment.
Cooperative Inverse Reinforcement Learning, which shows how to expand the action space of the agent through a human "teaching" the robot new behaviors.
The Booths and Show Floor
Besides the sessions, there was a show floor that mostly had booths from several large tech companies (as well as some head scratchers like Wayfair). The floor was quite spacious, and it was fun to walk around between sessions. Additionally, every two-three hours, they would stock a ring of stations around the booths with coffee, tea, and pastries, which was quite nice.
Some of the booths were there to demonstrate new tech, such as Nvidia's live image editing technology:

Google's booth gave several demonstrations of Tensorflow Hub which they launched earlier this year. Most of booths however were mainly focused on recruiting and talking to potential candidates.
It wasn't surprising to see booths like Google, Baidu, Netflix, Microsoft, and Facebook with several representatives from their data science teams. Many of them were giving talks during the sessions as well. However, a notable absence on the show floor was the lack of representation from Apple.
Considering how well-known it's become that Apple is far behind in their AI technology, you would think they would be fighting hard for AI talent. Many newly stamped PhD students were walking around the floor, and several of them crowded around the booths of Silicon Valley companies. Instead of competing for this talent pool though, Apple was basically a non-presence at the conference.

Final Thoughts
ICML 2018 was one of the best-run conferences I've ever been to. Almost every session started on-time, and there was enough seating no matter which session you attended. The conference space was very modern, and the check-in process was quick and easy. They even included a free transit pass so you could get to the conference for free or explore Stockholm in your free time.
Most sessions only lasted 10 minutes, which sounds quite short for a presentation, but it forced the speakers to make the most of their time. As a result, it was easy to stay engaged despite listening to hours of technical talks. At the end of each day, there were networking sessions and a chance to meet with speakers and ask them questions about their research.
In general, Mux had a great time at our first ICML. We hope to expand our presence at future ICMLs, and we are looking forward to translate some of our learnings into cutting-edge AI features for Mux Video.


