Every engineer has faced unexpected bugs that defy logic and test patience. Whether you're debugging a mobile app, a backend service, or a complex video streaming platform, the challenge is often the same: find the root cause and fix it before it causes more issues.
We faced one such bug recently here at Mux. A bug that hides faster than a cockroach at 2:30 AM as soon as you turn the lights on to look for it. Gather ‘round, kids, this time, it was a doozie.
The mystery of the SRT disconnect
Recently one of our customers ran into a problem with our recently released Secure Reliable Transport (SRT) support.
Every day, at the exact same time each day, all their SRT (but not RTMP) live streams stopped working — switching to a slate image or otherwise failing. These live streams were coming from different encoders and from different locations, yet were failing at the same time.
This didn’t seem to be an infrastructure problem at Mux’s end — the streams were coming into different instances of our SRT edge infrastructure, and being processed by different origin servers.
So what could possibly cause these to fail all at exactly the same time? We set to work, trying to understand what was going wrong here.
Stones Requiring Turning (get it?)
The first things we looked at were the source recordings from the live stream and the Live Stream Input Health dashboard page. Curiously, these two sources disagreed about what was happening. According to the live health page, we continued to receive the live stream at 60 fps throughout, as the customer expected. But our source recordings had other ideas. It was showing timestamps that went backwards, frame rates jumping around wildly, and bitrates changing dramatically.
What was going on here? Well, let's take a closer look at how Mux live streaming works for an SRT stream.
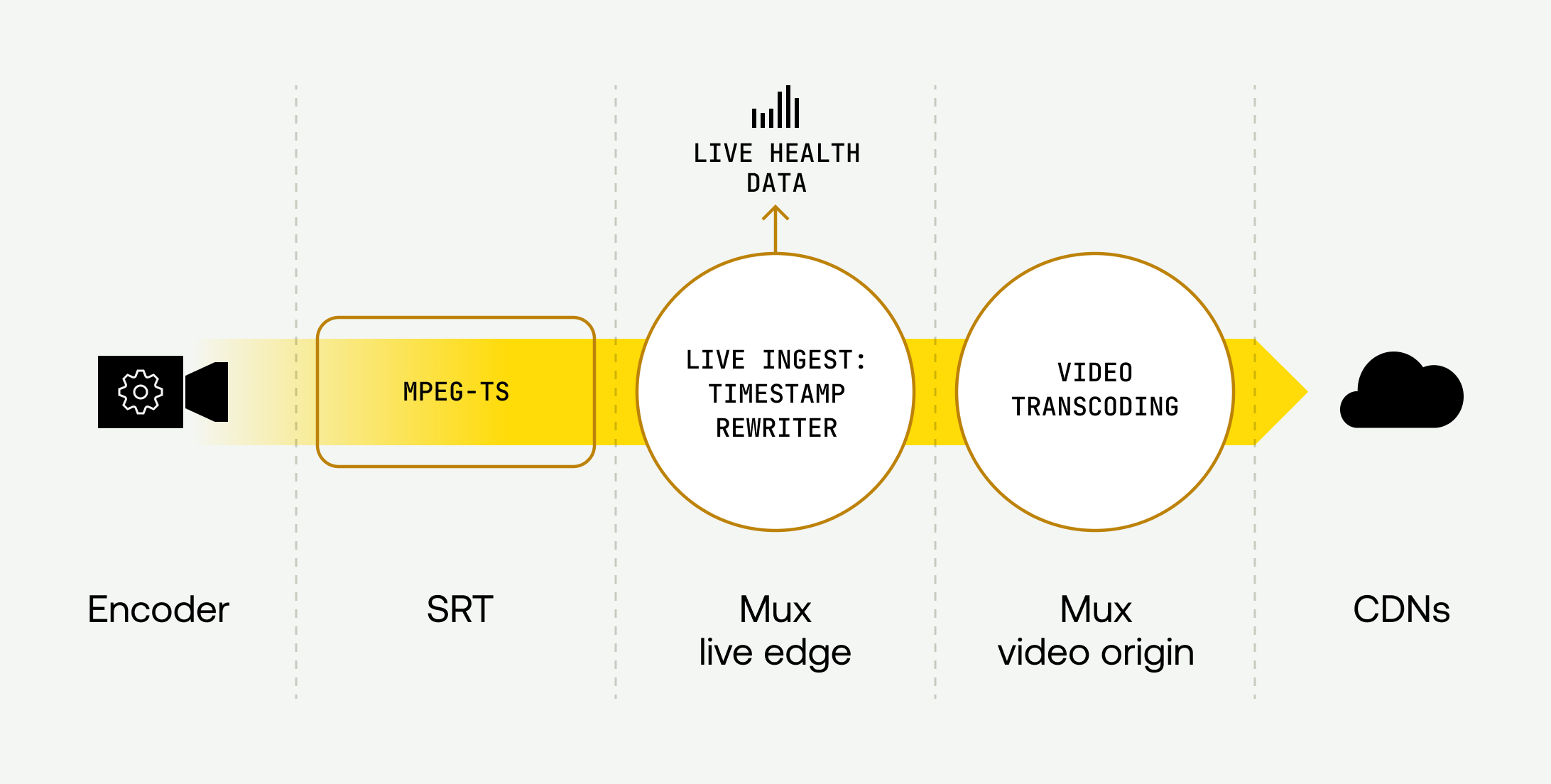
SRT encapsulates an MPEG-TS media stream. MPEG-TS has a couple of different forms of timestamps in it: the Program Clock Reference (PCR), which allows long-running synchronization of various streams, and then each Program Elementary Stream (PES) data stream (typically, one for video and one for audio) has its own timestamps giving per frame timing information.
Our first clue about the problem was realising that the PES timestamps recorded in Mux’s source recordings aren't the original values from the encoder, they're modified when we receive them — we rewrite the timestamps to create a continuous stream even after a reconnect. So, maybe those backwards timestamps in our recordings weren't from the encoders, but were a sign of a Mux bug… was this a problem with the encoder, or something Mux was doing wrong?
The next clue we found was noticing that the PCR timestamps, which we don't rewrite, wrapped around.
In most media formats, there’s a maximum value for a timestamp, and if you go beyond that it rolls over back to zero. That zero should be interpreted as being more than the previous very big value. Confusing! Sometimes, this behaviour doesn’t matter — the maximum might be hundreds of years in the future, and if we cause problems for our great, great, great, great grandchildren, well… sorry. But for some formats, this rollover can happen much sooner.

The timestamps in MPEG-TS roll over roughly every 26.5 hours, because they use only 33 bits (and the clock runs at 90kHz). We don't usually expect this to be a problem, because Mux live streams are only allowed to be a maximum of 12 hours long. But, an encoder isn't required to start from zero. It seems like the encoders this customer was using start timestamps at a different value, based on the real clock time — and so this wraparound was happening at the same time of day every time. Whenever they started a stream, the timestamps represented the current time of day — and then kept counting after midnight. At around 2:30 AM, 26.5 hours after midnight of the day the encoders were started, they encountered this problem.
Mux Live doesn't use the PCR timestamps, but it seemed like a good bet that the PES timestamps were doing the same — confusing our timestamp rewriter, and causing us to record messed up data in our source recordings (but not in our live health system, which continued to say the stream was healthy — because it was).
The timestamp rewriter saw the timestamps going backwards and doesn’t allow this, so it rewrote the timestamps, bumping them forward in time by a tiny amount. As a consequence, further downstream in our systems, we saw that we weren’t receiving enough video frames in time, causing us to (depending on whether slates were enabled on this stream) either disconnect the stream or start inserting a slate.
Implementing the fix (and stopping it from happening again)
We hadn't seen this before. RTMP timestamps only roll over after a little over 49 days, and for RTMP, encoders almost always start from zero. We hadn't run into this case in our testing because all the SRT encoders we tested with also started from zero.
Once we understood the problem, we were able to fix it quickly: our timestamps rewriter needed to handle wraparound in the PES timestamps We added in some code to handle this: detecting the timestamps going from a very big value (around 8 billion) to a very small value (around 0), and treating that as a normal monotonically-increasing timestamp.
Time to wrap around some lessons learned
Live streaming has a lot of exciting special cases (and not always in a good way). Even after running Mux Live for years, we continue to learn about new edge cases as we roll out new features.
Here are a few lessons we relearned in the process of getting to the bottom of this one:
- Consider all permutations of your data types: as shown in this case, a timestamp is not a timestamp is not a timestamp. Being aware and coding defensively against these intricacies can save you a ton of time and frustration.
- Monitoring is a superpower: our Live Stream Input Health dashboard and source recordings provided different insights that were critical in diagnosing the problem. Use the tools you have configured to help you uncover additional information related to the issue (or, set up logging and monitoring if you haven’t already.)
- When you think you’ve tested all edge cases, think again: seriously, it’s impossible to rule out every edge case. Stay nimble and collaborate with a solid team to react to bugs like this in a timely manner.