
Using Erlang’s OTP and Phoenix’s Channel / Presence to manage large real-time data sets across many channel topics
Our real-time analytics product requires a scalable system with high availability and support for thousands of concurrent processes. Luckily, our API is built upon a technology that was made for just that: Elixir.
Elixir is a functional language that runs on the Erlang VM and is able to leverage the Erlang ecosystem, most importantly OTP (Open Telecom Platform), which was originally designed for fault tolerant, concurrent telecommunication distribution in the late 1980’s. Though historically a somewhat obscure programming language, Erlang is gaining traction due to Elixir’s modern design implementation and the increasing need for highly available, concurrent systems on the web (think massively multiplayer online gaming and internet chat apps).
At Mux, we didn’t have the pressing need to utilize the full capabilities of Erlang’s OTP. We were using Elixir on our REST API for its functional design patterns and concurrent architecture. However, when we started development on our real-time product, we quickly realized that we didn’t have to introduce any external technologies. Everything that was necessary to build a performant and robust real-time system existed within OTP and the Elixir web framework, Phoenix.
Before we could start development, we had some constraints and requirements that needed consideration. Firstly, the datastore we’re using fits our use case and is extremely efficient for querying large datasets, but it only supports a SQL-like interface and doesn’t offer any kind of pubsub model. Secondly, and more importantly, we wanted to control the story around how and when that datastore is queried. Because of this, we decided to go with a system that allows us to query our datastore on our terms and provides a simpler interface to the client that allows it to subscribe to specific updates instead of polling various endpoints. Phoenix allowed us to architect this easily with a robust WebSocket and PubSub framework and Elixir gave us the the ability to create a process driven subscription querying system complete with dynamic supervision and fault tolerance.
Communicating through WebSockets
Most real-time web applications are using the WebSocket protocol either directly or indirectly through a framework (like Socket.io) to relay information between the server and the client. The Phoenix framework has a WebSocket framework built in, which can be easily interfaced with the Socket and Channel modules. Phoenix even provides a PubSub layer and has support for Redis for applications unable to use the built in clustering mechanisms.
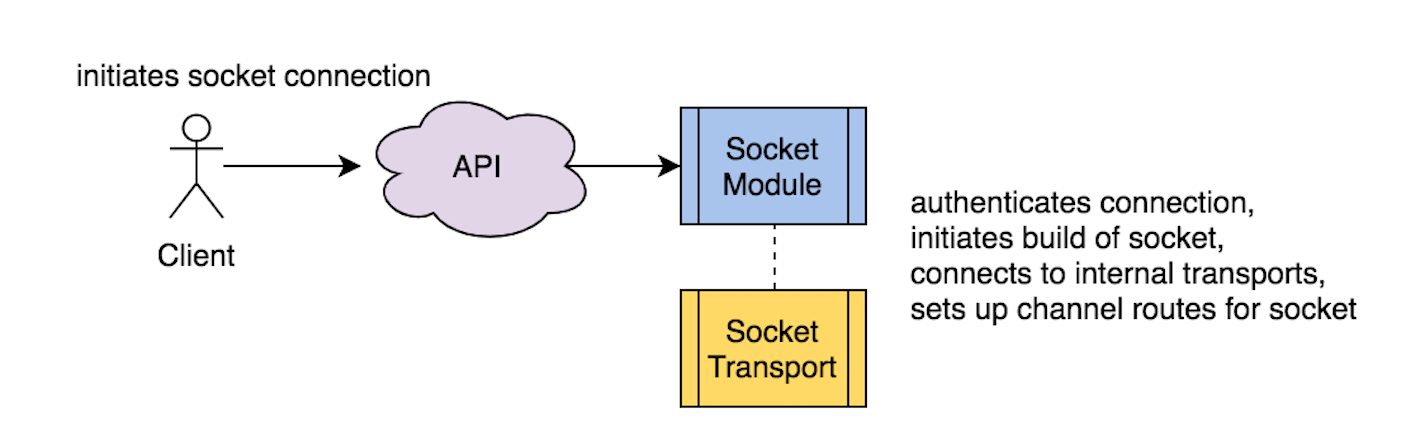
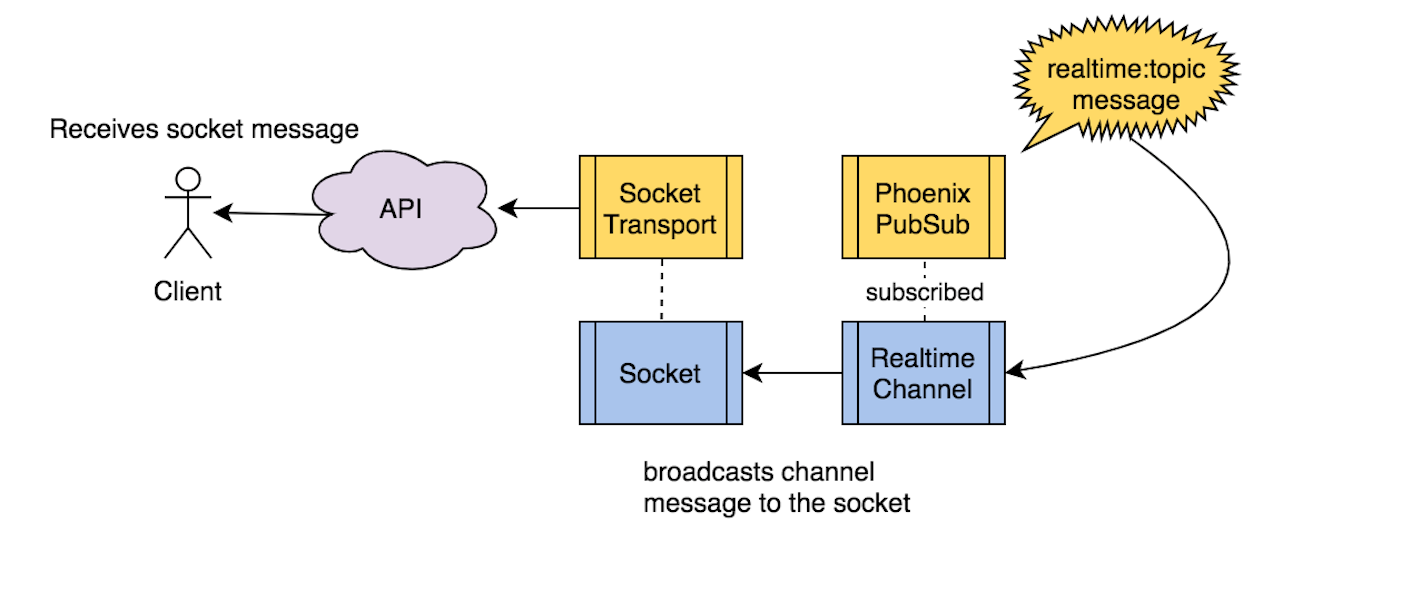
We use the Socket module to authenticate an incoming WebSocket connection. Once authenticated, the Socket module uses the internal Socket.Transport module to build the socket state and create channel routes to allow for broadcasting messages to the socket.
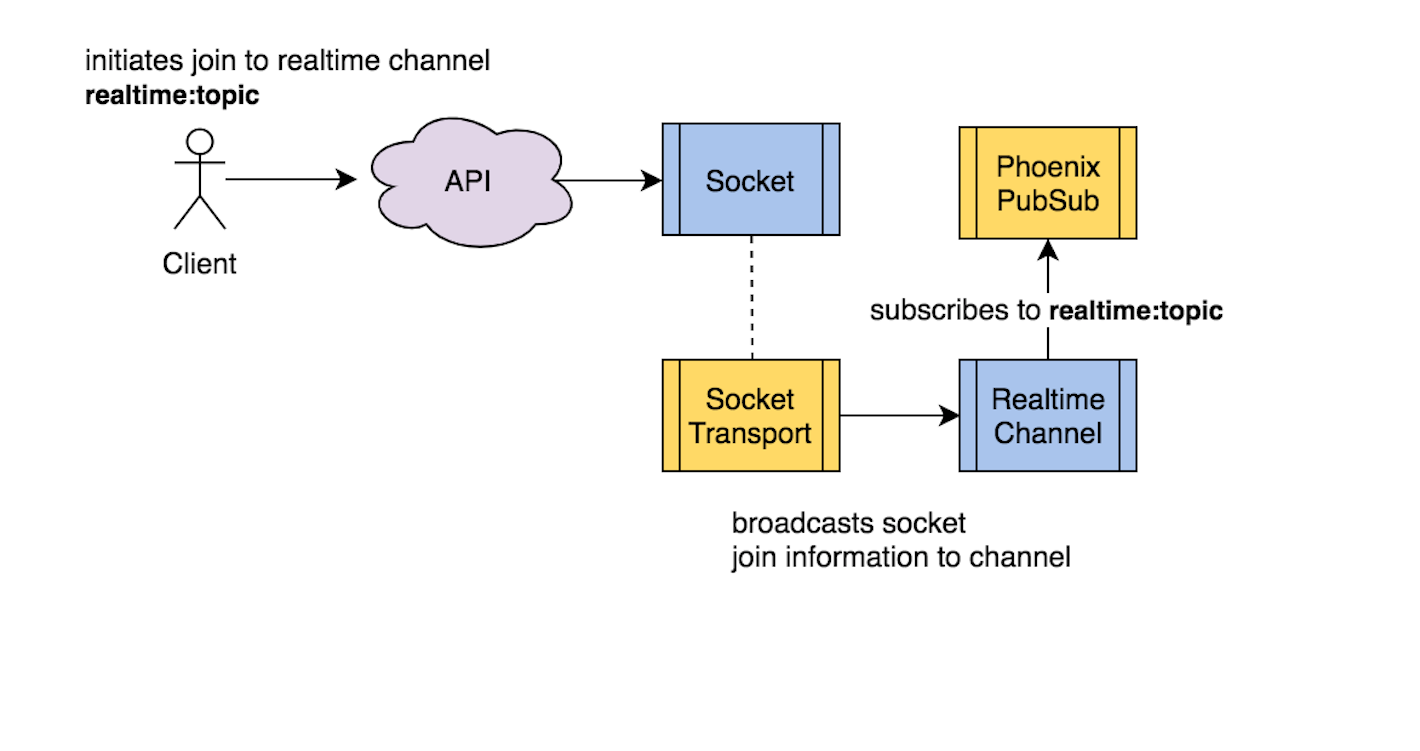
The Channel module is an implementation of a GenServer with join callback functions that allow for sockets to join channel topics. When a user socket joins a channel topic and the join callback function is executed, a new Phoenix.Channel.Server process is created that subscribes to the joined channel topic (in our case realtime:topic) on the internal PubSub.
Anyone not totally familiar with Erlang might think that’s a recipe for a lot of processes since every connection (essentially every browser tab open) joining a channel creates a channel process. However, that’s exactly what Erlang is optimized for; everything in Erlang is a lightweight process that communicates by sending and receiving messages.
Each Phoenix.Channel.Server process holds the joined socket in its state and is used to relay channel information to and from the socket. When a message is broadcast to a channel topic from the PubSub, each of these channel processes that have subscribed to the PubSub will receive the message and send it to the socket in their state. Additionally, when a socket leaves a channel, its channel process stops tracking the socket and is removed from the system.
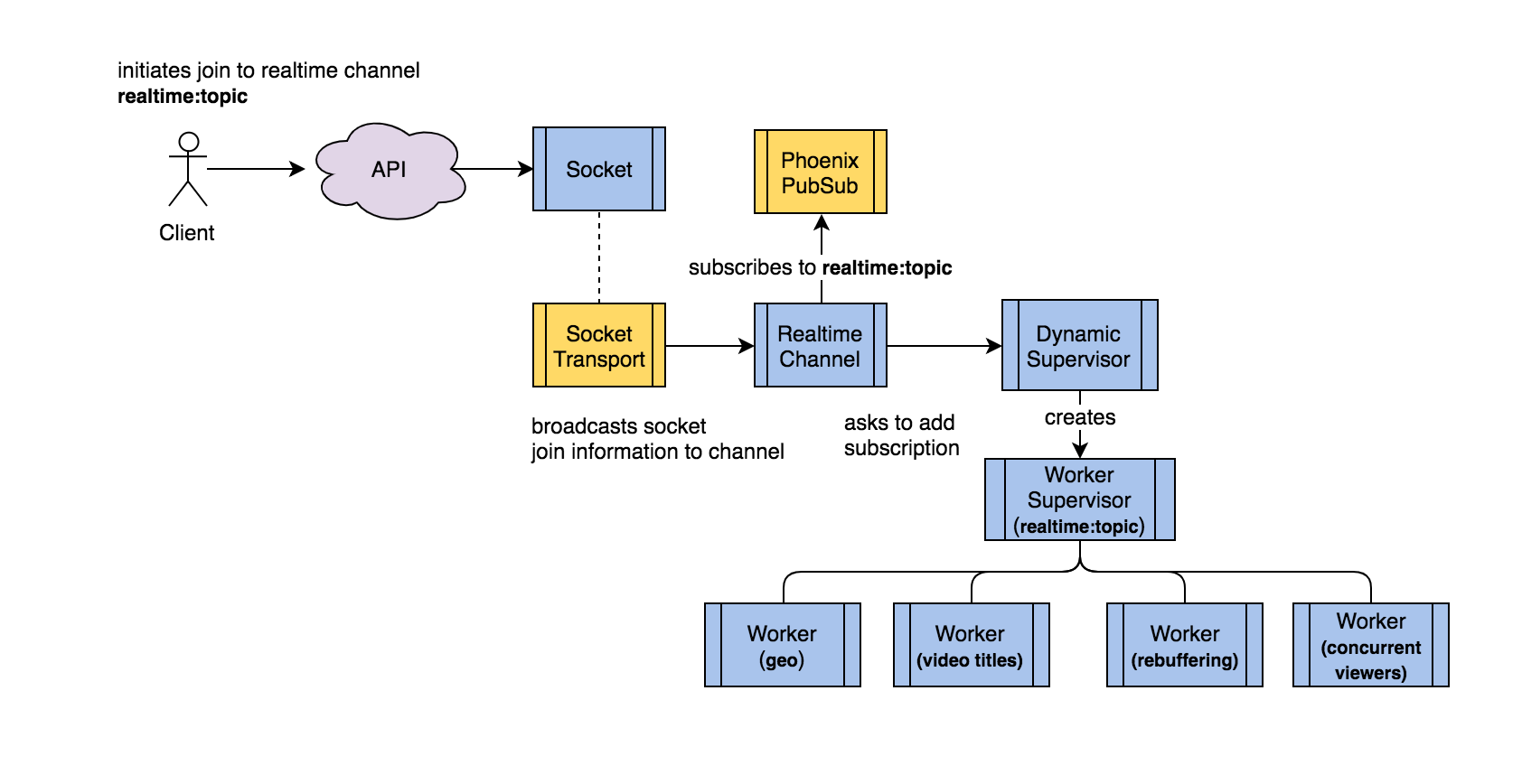
Managing subscriptions with Dynamic Supervisors
Currently, we display four sets of analytics on our real-time dashboard at five second intervals. We needed a way to dynamically spin up processes to request that information when a new real-time subscription is added. Conveniently, Elixir has a type of process called a DynamicSupervisor, which can be used to dynamically create and manage child processes. When a user joins a real-time channel, we ask our DynamicSupervisor to create a new child process, which is actually a Supervisor itself. Each dynamically created Supervisor process creates a process for each of our data types.
Information polling with GenServer processes
We need to access information from our real-time database for each data type at five second intervals. This is one of those tasks that is made extremely easy with Elixir. We need supervised, isolated processes that are responsible for polling our database at set intervals. To facilitate this, Elixir has a module called a GenServer , which is a separate process that can hold state and is specifically designed to be added to supervision trees.
Each of our real-time workers is an implementation of a GenServer that holds information about the subscription, request interval, and which data type it is requesting information for. First, we have a worker send itself a :poll message after five seconds have passed. Then, we utilize the GenServer callback function handle_info to listen for the :poll message. Once the message has been received, we make a database request for the subscription’s specific request type, which we have in our GenServer state. After the request is made, we call the schedule_poll function again to kick off another request after five seconds have passed.
@impl true
def handle_info(:poll, state) do
initiate_realtime_request(state)
schedule_poll()
{:noreply, state}
end
defp schedule_poll() do
Process.send_after(self(), :poll, @interval)
endIsolating process crashes
We don’t want all of our customer real-time dashboards to be affected when one of our DynamicSupervisor’s child processes crashes. Thankfully, the only supported strategy for a DynamicSupervisor is :one_for_one, which means if a child process terminates, it won’t terminate any of the other child processes being managed by the same supervisor.
@impl true
def init(_args) do
DynamicSupervisor.init(strategy: :one_for_one)
endSince one failing real-time worker shouldn’t affect other workers, we apply the same strategy for our child Supervisors.
@impl true
def init([subscription_id]) do
children = [
{Worker, [..., :concurrent_viewers_by_country]},
{Worker, [..., :time_series]},
{Worker, [..., :startup_time]},
{Worker, [..., :top_concurrent_video_title]}]
Supervisor.init(children, strategy: :one_for_one)
endThe :restart setting on a DynamicSupervisor, Supervisor, and GenServer module is set to :permanent by default. This means when any of these processes crash in an unexpected way, they will be restarted, which happens very quickly and is a great scenario for a process that is meant to deliver information in real-time to a monitored dashboard.
Preventing subscription duplication across nodes
Like most distributed web applications, our API is multi node within a connected cluster that sits behind a load balancer. Because of this, duplicate topic subscriptions is a problem we knew we would need to solve since a user’s connection can be routed to any given API node in the cluster.
In our system, one user can create multiple WebSocket connections for the same channel topic and multiple users can also subscribe to the same channel topic. This creates a scenario where one WebSocket that is connected to an API node can subscribe to a channel topic and another WebSocket connected to a different API node can subscribe to the same channel topic, causing duplicate supervision trees that are polling for the same information.
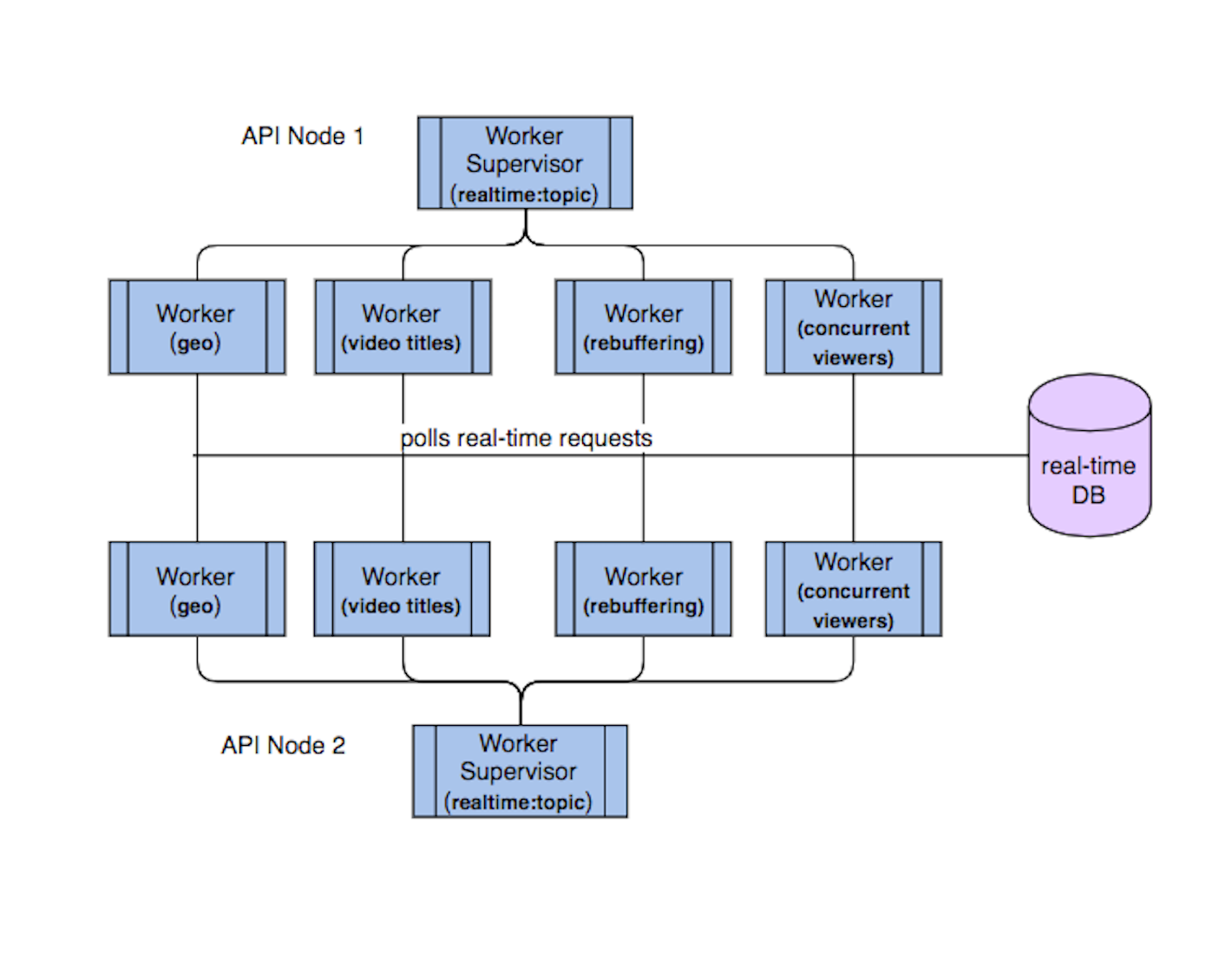
This situation isn’t ideal for a couple of reasons. For one, it’s wasteful; we’d have duplicate processes making unnecessary queries, meaning both our application and real-time database are doing more work than they need to. Secondly and more importantly, users are receiving multiple messages with the same data, or worse, data that is out of order due to timing differences between API nodes.
To solve this problem, we use two features that are core to Erlang: globally registered processes and process monitors. When a process name is globally registered, it is accessible across all connected nodes in a cluster.
{:ok, _} = Supervisor.start_link(__MODULE__, name:{:global, channel_topic})Using this feature, we first check if the process is globally registered before creating a new real-time Supervisor. If it is not, we create a Supervisor and globally register it with the channel topic name. This ensures only one real-time supervision tree exists per channel topic across all nodes in the cluster.
Though, what happens when the node hosting the global process is removed from the cluster? We would need a way to recreate that process on one of the remaining nodes, otherwise users would stop seeing real-time data on existing connections. To avoid this, we use Elixir’s Process module and its monitor function to make sure a process always exists when it is expected to.
@impl true
def handle_cast({:monitor_process, [subscription_id]}, _state) do
with pid when pid !== :undefined
<- :global.whereis_name(subscription_id) do
Process.monitor(pid)
{:noreply, _state}
end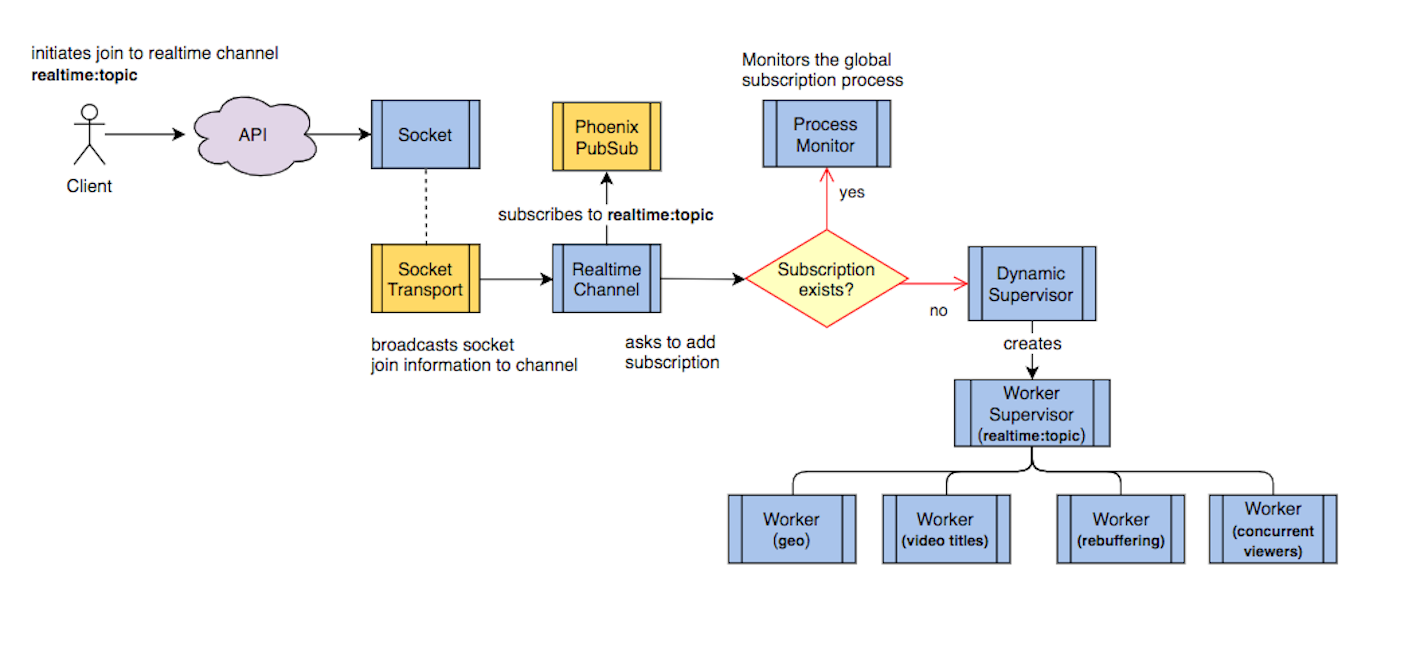
If the global process exists, we monitor it within our ProcessMonitor module and use the handle_info callback to listen for the :DOWN event message. Since this event message is also sent for legitimate subscription removals, we check to make sure the reason is not :normal before we recreate the process supervision tree on the current node.
@impl true
def handle_info({:DOWN, ref, :process, pid, reason}) do
Process.demonitor(ref, [])
if reason != :normal do
... add subscription logic ...
end
end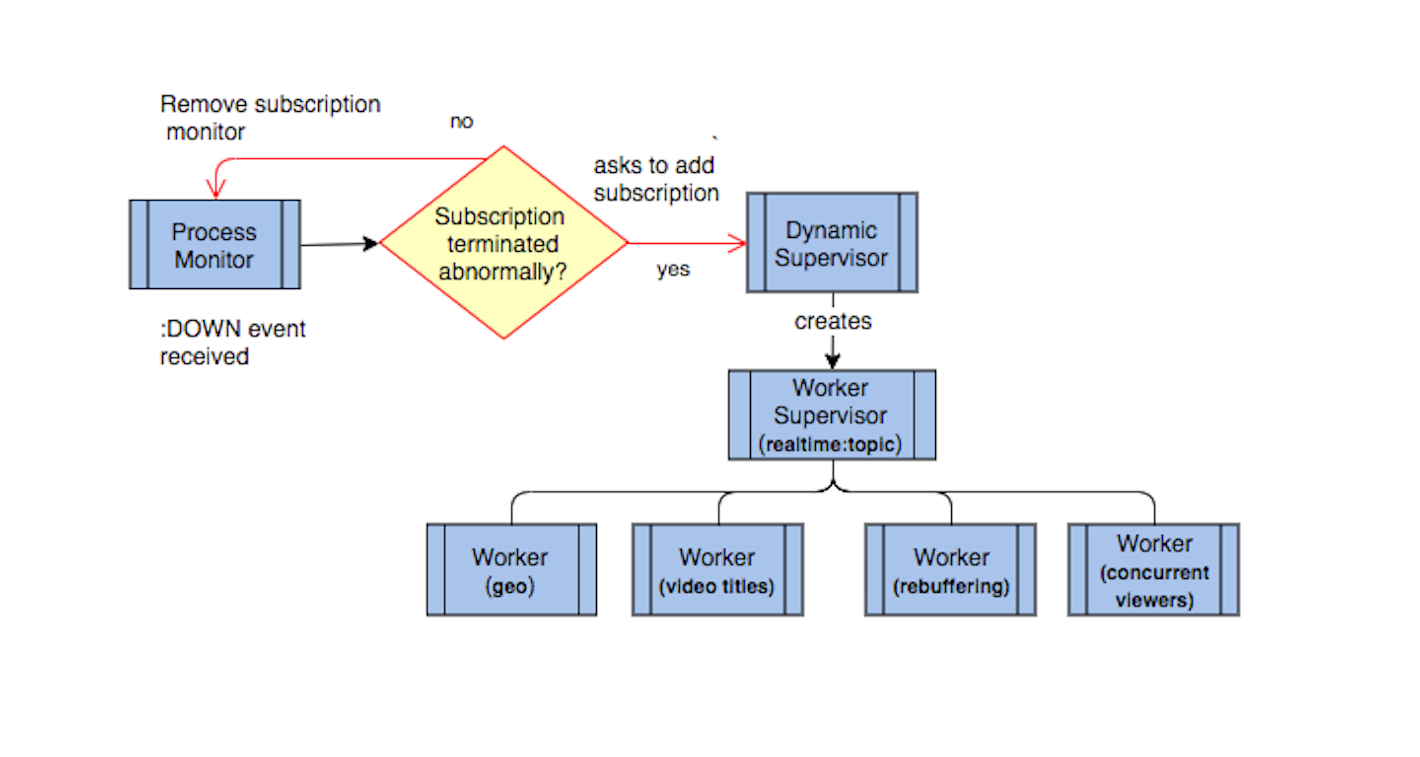
Keeping subscription state server-side with Presence
We covered subscription process creation, but what about subscription process removal? When all sockets have left a channel topic, we need a way to remove the associated processes to free up server resources and to make sure we're not unnecessarily polling our database. One solution is to keep socket subscription states in a globally accessible store. When a socket leaves a channel topic, we can check the store to see if there are any sockets still subscribed to that channel topic and remove the subscription processes if there are not.
As it turns out, Phoenix has a built in socket subscription store called Presence. Presence is usually used for updating state on the client, but we decided it would be pretty neat to use it to keep track of our subscription state on the server.
Presence uses Phoenix Tracker, which is a distributed module that sends a heartbeat with presence information stored independently on each of the connected nodes in a cluster. The Presence module can be used to request socket channel references. It can also be used to track socket channel join and leave events.
When a user socket joins a channel topic, we use the Channel module’s handle_info callback function to ask Presence to track the socket after it successfully joins.
@impl true
def handle_info(:after_join, socket) do
Presence.track(socket, socket.assigns.topic, %{
online_at: inspect(System.system_time(:seconds))
})
{:noreply, socket}
endWhen a socket is tracked, Presence will send out a presence_diff event to the socket’s channel topics with join and leave information.
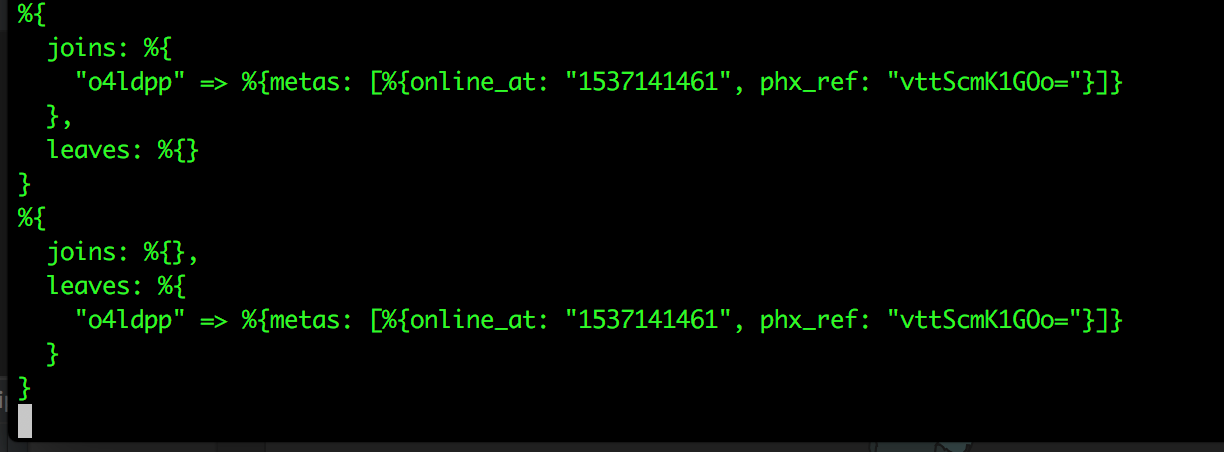
Presence has a list function that returns a list of socket references for a tracked topic.
Presence.list(channel_topic)[id][:metas]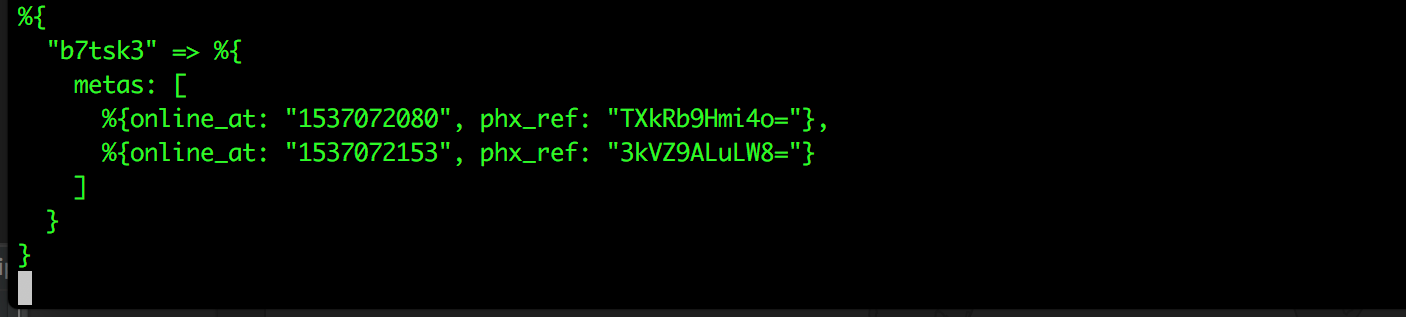
Using this information, we know when a socket leaves a channel topic and can check to see if there are any sockets still subscribed. If there are no sockets subscribed, we can remove the processes we created for that channel topic. One way to do this is to subscribe to a channel topic from a separate GenServer process. Once subscribed, the handle_info callback function is used to listen for messages broadcast from the PubSub to the channel topic. Since the last socket leaving a channel topic will trigger a presence_diff event, we filter specifically for presence_diff events and use the Presence.list function to determine if there are sockets still being tracked by Presence.
@impl true
def handle_info(broadcast = %Socket.Broadcast{}, _state) do
with event when event in ["presence_diff"]
<- broadcast.event,
["realtime", topic] <- String.split(broadcast.topic, ":"),
nil <- Presence.list(broadcast.topic)[topic][:metas]
do
handle_subscription_leave(broadcast.topic)
end
{:noreply, _state}
end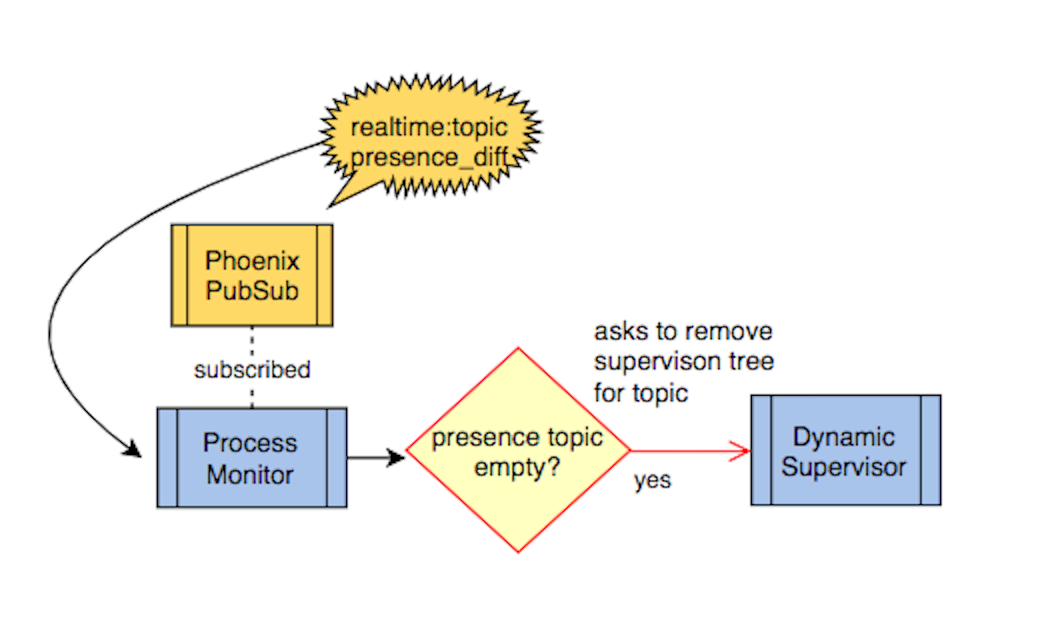
That’s it, no additional frameworks necessary. Everything we used to build our real-time architecture exists within Phoenix and Elixir. If you're just using Phoenix for your REST API, I highly recommend taking a closer look at the options made available by Elixir and OTP when you plan for your next project. It might just save you from adding unnecessary dependencies and you’ll learn a lot about Erlang and OTP in the process.
Technical considerations
Presence is eventually consistent
Presence is distributed across all nodes in a cluster and nodes might have different Presence information since they're not updated at the same time. This isn’t a problem for us since we only rely on Presence for telling us when a channel topic list is empty and we know the node hosting our subscription process will eventually (and quickly) be given that information.
Race conditions
Our real-time system has a lot of moving asynchronous parts, which leaves room for occasional race conditions. However, the only race condition that we could envision (because we haven’t seen it happen yet) is an extremely rare occurrence of a subscription joining while a process with the same subscription ID is in the process of being torn down. This is rare because our subscription removals happen nearly instantaneously. This also doesn't have significant consequences for us since a page refresh would resolve the issue, but it's worth mentioning in case this situation could lead to bigger issues in other use cases.
Zombie processes
There is always the possibility that a process is not cleaned up properly and continues to poll our database. Though this should be an extremely rare occurrence, we created tools to identify and remove global real-time processes in our system that exist without sockets (with the help of Presence and Erlang).
Soft real time
Erlang provides soft real time, meaning some delivery deadlines might be missed. This isn’t a problem for us because we can get missed information in the next successful request. If you are building a real-time system that must have every deadline met and you do not have access to missed information, this approach might not be for you.
Resource management
Our API node needs resources available in order for us to have a functional API and isn’t an ideal place for these polling processes. Luckily, Erlang processes are isolated and can be easily moved to a different node as long as it’s connected to the cluster. We group everything in our API for simplicity in this blog post, but the actual processes may live elsewhere in our architecture.
As always, if you have any comments or questions, please let us know.


