
Tensorflow has grown to be the de facto ML platform, popular within both industry and research. The demand and support for Tensorflow has contributed to host of OSS libraries, tools and frameworks around training and serving ML models. The Tensorflow Serving is a project built to focus on the inference aspect for serving ML models in a distributed, production environment.
Mux uses Tensorflow Serving in several parts of its infrastructure, and we’ve previously discussed using Tensorflow Serving to power our per-title-encoding feature. Today, we’ll focus on techniques that improve latency by optimizing both the prediction server and client. Model predictions are usually “online” operations (on critical application request path), thus our primary optimization objectives are to handle high volumes of requests with as low latency as possible.
First let’s do a quick overview of Tensorflow Serving.
What is Tensorflow Serving?
Tensorflow Serving provides a flexible server architecture designed to deploy and serve ML models. Once a model is trained and ready to be used for prediction, Tensorflow Serving requires the model to be exported to a Servable compatible format.
A Servable is the central abstraction that wraps Tensorflow objects. For example, a model could be represented as one or more Servables. Thus, Servables are the underlying objects that client uses to perform computation such as inference. The size of Servable matters, as smaller models use less memory, less storage, and will have faster load time. Servables expect models to be in SavedModel format for loading and serving with the Predict API.
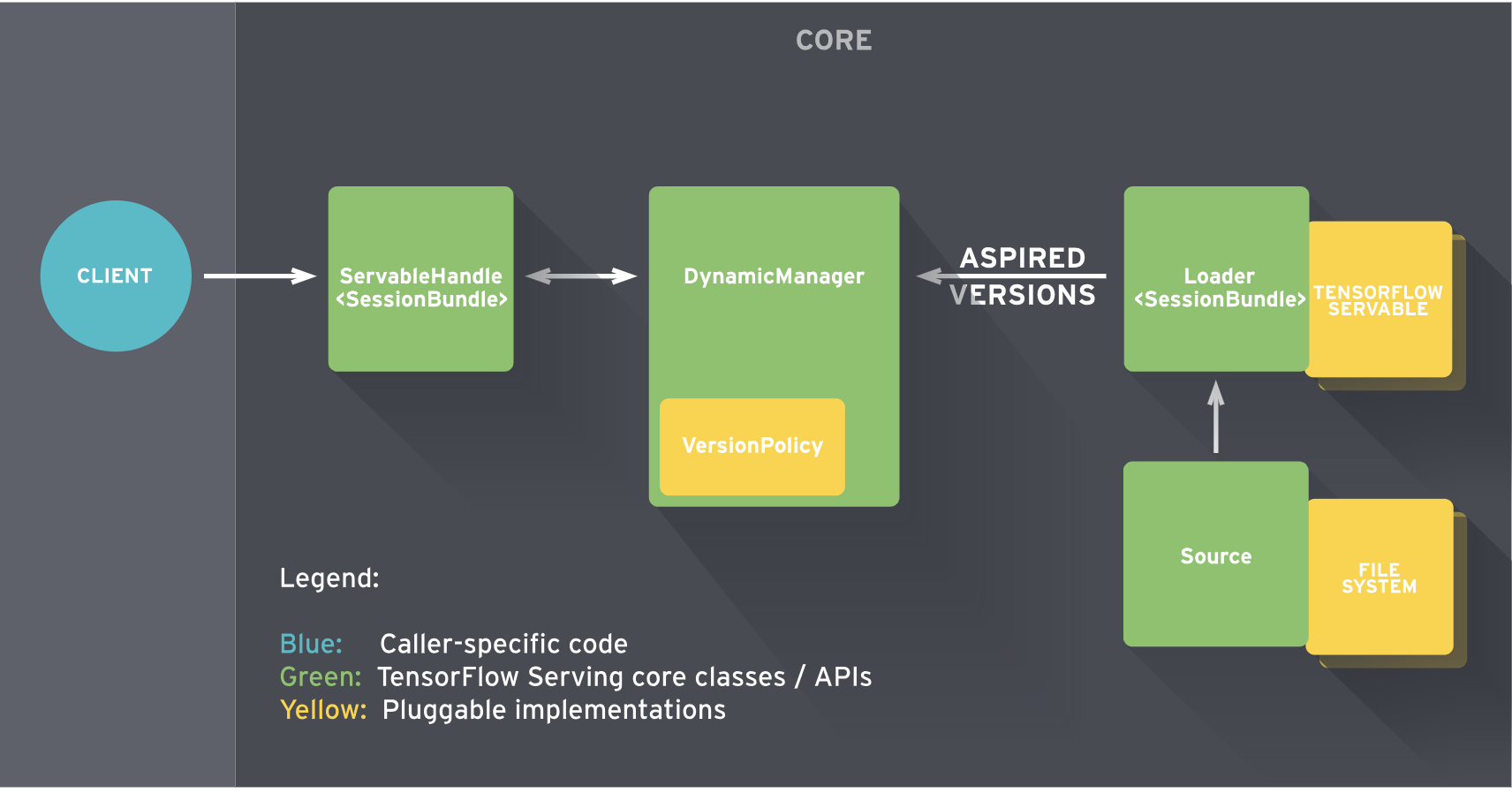
Tensorflow Serving puts together the core serving components to build a gRPC/HTTP server that can serve multiple ML models (or multiple versions), provide monitoring components, and a configurable architecture.
Tensorflow Serving with Docker
Lets get a base-line prediction performance latency metric with the standard Tensorflow Serving (no CPU optimizations).
First, pull the latest serving image from Tensorflow Docker hub:
docker pull tensorflow/serving:latestFor the purpose of this post, all containers are run on a 4 core, 15GB, Ubuntu 16.04 host machine.
Export Tensorflow model to SavedModel format
When a model is trained using Tensorflow, the output can be saved as variable checkpoints (files on disk). Inference can be run directly by restoring model checkpoints or on its converted frozen graph (binary).
In order to serve these models with Tensorflow Serving, the frozen graph has to be exported into SavedModel format. Tensorflow documentation has examples on exporting trained models in SavedModel format.
Tensorflow also provides a host of official and research models as starting point for experiments, research or production use.
As an example, we will use the deep residual network (ResNet) model that can be used to classify ImageNet’s dataset of 1000 classes. Download the pre-trained ResNet-50 v2 model, specifically the channels_last (NHWC) convolution SavedModel, which is generally better for CPUs.
Copy the RestNet model directory in the following structure:
models/
1/
saved_model.pb
variables/
variables.data-00000-of-00001
variables.indexTensorflow Serving expects models to be in numerically ordered directory structure to manage model versioning. In this case, the directory 1/ corresponds to model version 1, which contains the model architecture saved_model.pb along with snapshot of the model weights (variables).
Load and serve SavedModel
The following command spins up a Tensorflow Serving model server in docker container. In order to load the SavedModel, the model’s host directory needs to be mounted into the expected container directory.
docker run -d -p 9000:8500 \
-v $(pwd)/models:/models/resnet -e MODEL_NAME=resnet \
-t tensorflow/serving:latestInspecting the container logs show that the ModelServer is running and ready to serve inference requests for resnet model on gRPC and HTTP endpoints:
...
I tensorflow_serving/core/loader_harness.cc:86] Successfully loaded servable version {name: resnet version: 1}
I tensorflow_serving/model_servers/server.cc:286] Running gRPC ModelServer at 0.0.0.0:8500 ...
I tensorflow_serving/model_servers/server.cc:302] Exporting HTTP/REST API at:localhost:8501 ...Prediction Client
Tensorflow Serving defines the API services schema as protocol buffers (protobufs). The gRPC client implementations for the prediction API is packaged as tensorflow_serving.apis python package. We will also need the tensorflow python package for utility functionalities.
Lets install dependencies to create a simple client:
virtualenv .env && source .env/bin/activate && \
pip install numpy grpcio opencv-python tensorflow tensorflow-serving-apiThe ResNet-50 v2 model expects floating point Tensor inputs in a channels_last (NHWC) formatted data structure. Hence, the input image is read using opencv-python which loads into a numpy array (height x width x channels) as float32 data type. The script below creates the prediction client stub and loads JPEG image data into numpy array, converts to Tensor proto to make the gRPC prediction request:
The output of running the client with an input JPEG image is shown below:
python tf_serving_client.py --image=images/pupper.jpg
total time: 2.56152906418sThe output Tensor has the prediction result as an integer value and probabilities of features.
outputs {
key: "classes"
value {
dtype: DT_INT64
tensor_shape {
dim {
size: 1
}
}
int64_val: 238
}
}
outputs {
key: "probabilities"
...For a single request, this kind of prediction latency is unacceptable. However, this is not totally unexpected; the default Tensorflow Serving binary targets the broadest range of hardware to cover most use cases. You may have noticed from the standard Tensorflow Serving container logs:
I external/org_tensorflow/tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMAThis is an indication of Tensorflow Serving binary running on an incompatible CPU platform that it was not optimized for.
Building CPU optimized serving binary
According to Tensorflow documentation, it is recommended to compile Tensorflow from source with all the optimizations available for the CPU of the host platform the binary will run on. The Tensorflow build options expose flags to enable building for platform-specific CPU instruction sets:
Instruction SetFlagsAVX--copt=-mavxAVX2--copt=-mavx2FMA--copt=-mfmaSSE 4.1--copt=-msse4.1SSE 4.2--copt=-msse4.2All supported by processor--copt=-march=native
Clone Tensorflow Serving pinned to specific version. In this case, we’ll be using 1.13 (latest as of this publishing this post):
USER=$1
TAG=$2
TF_SERVING_VERSION_GIT_BRANCH="r1.13"
git clone --branch="$TF_SERVING_VERSION_GIT_BRANCH" https://github.com/tensorflow/servingTensorflow Serving development image uses Bazel as the build tool. Build targets for processor-specific CPU instruction sets can be specified as follows:
TF_SERVING_BUILD_OPTIONS="--copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-msse4.1 --copt=-msse4.2"If memory is a constraint, limit the consumption of the memory intensive build process with --local_resources=2048,.5,1.0 flag. See Tensorflow Serving with Docker and Bazel docs as resources on such build flags.
Build the serving image with development image as base:
ModelServer can be configured with Tensorflow-specific flags to enable Session parallelism. The following options configure two thread pools to parallelize executions:
intra_op_parallelism_threads
- controls maximum number of threads to be used for parallel execution of a single operation.
- used to parallelize operations that have sub-operations that are inherently independent by nature.
inter_op_parallelism_threads
- controls maximum number of threads to be used for parallel execution of independent different operations.
- operations on Tensorflow Graph that are independent from each other and thus can be run on different threads.
The default for both options are set to a value of 0. This means, the system picks an appropriate number, which most often entails one thread per CPU core available. However, this can be manually controlled for multi-core CPU parallelism.
Next, start the serving container similarly to before, this time with the docker image built from source and with Tensorflow specific CPU optimization flags:
docker run -d -p 9000:8500 \
-v $(pwd)/models:/models/resnet -e MODEL_NAME=resnet \
-t $USER/tensorflow-serving:$TAG \
--tensorflow_intra_op_parallelism=4 \
--tensorflow_inter_op_parallelism=4The container logs should not show CPU guard warnings anymore. Without changing any code, running the same prediction request drops the prediction latency by ~35.8%:
python tf_serving_client.py --image=images/pupper.jpg
total time: 1.64234706879sImproving speed on prediction client
Can we do better? Server side has been optimized for its CPU platform but a prediction latency over 1s still seems too high.
It just so happens that there is a large latency cost to loading the tensorflow_serving and tensorflow libraries. Each call to tf.contrib.util.make_tensor_proto also adds an un-necessary latency overhead as well.
“Hold up”, you might be thinking. “Don’t I need the Tensorflow Python packages to actually make prediction requests to Tensorflow Server?”
The simple answer is no, we don’t actually need the tensorflow or tensorflow_serving packages to make prediction requests.
As noted previously, Tensorflow prediction APIs are defined as protobufs. Hence, the two external dependencies can be replaced by generating the necessary tensorflow and tensorflow_serving protobuf python stubs. This avoids the need the pull in the entire (heavy) Tensorflow library on the client itself.
To start with, get rid of tensorflow and tensorflow_serving dependencies and add grpcio-tools package.
pip uninstall tensorflow tensorflow-serving-api && \
pip install grpcio-tools==1.0.0Clone the tensorflow/tensorflow and tensorflow/serving repositories and copy the following protobuf files into the client project:
tensorflow/serving/
tensorflow_serving/apis/model.proto
tensorflow_serving/apis/predict.proto
tensorflow_serving/apis/prediction_service.proto
tensorflow/tensorflow/
tensorflow/core/framework/resource_handle.proto
tensorflow/core/framework/tensor_shape.proto
tensorflow/core/framework/tensor.proto
tensorflow/core/framework/types.protoCopying the above protobuf files into a protos/ directory and preserving the original paths:
protos/
tensorflow_serving/
apis/
*.proto
tensorflow/
core/
framework/
*.protoFor simplicity, the prediction_service.proto can be simplified to only implement the Predict RPC. This avoids pulling in nested dependencies of the other RPCs defined in the service. Here is an example of the simplified prediction_service.proto.
Generate the gRPC python implementations using grpcio.tools.protoc:
PROTOC_OUT=protos/
PROTOS=$(find . | grep "\.proto$")
for p in $PROTOS; do
python -m grpc.tools.protoc -I . --python_out=$PROTOC_OUT --grpc_python_out=$PROTOC_OUT $p
doneNow the entire tensorflow_serving module can be removed:
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2and replaced with the generated protobufs from protos/tensorflow_serving/apis:
from protos.tensorflow_serving.apis import predict_pb2
from protos.tensorflow_serving.apis import prediction_service_pb2The Tensorflow library is imported in order to use the helper function make_tensor_proto, which is used for wrapping a python/numpy object as TensorProto object.
Thus, we can replace the following dependency and code snippet:
import tensorflow as tf
...
tensor = tf.contrib.util.make_tensor_proto(features)
request.inputs['inputs'].CopyFrom(tensor)with protobuf imports and building the TensorProto object:
from protos.tensorflow.core.framework import tensor_pb2
from protos.tensorflow.core.framework import tensor_shape_pb2
from protos.tensorflow.core.framework import types_pb2
...
# ensure NHWC shape and build tensor proto
tensor_shape = [1]+list(img.shape)
dims = [tensor_shape_pb2.TensorShapeProto.Dim(size=dim) for dim in tensor_shape]
tensor_shape = tensor_shape_pb2.TensorShapeProto(dim=dims)
tensor = tensor_pb2.TensorProto(
dtype=types_pb2.DT_FLOAT,
tensor_shape=tensor_shape,
float_val=list(img.reshape(-1)))
request.inputs['inputs'].CopyFrom(tensor)Full python script available here. Run the updated inception client that makes prediction request to optimized Tensorflow Serving:
python tf_inception_grpc_client.py --image=images/pupper.jpg
total time: 0.58314920859sThe following chart shows latency of a prediction request against standard, optimized Tensorflow serving and client over 10 runs:
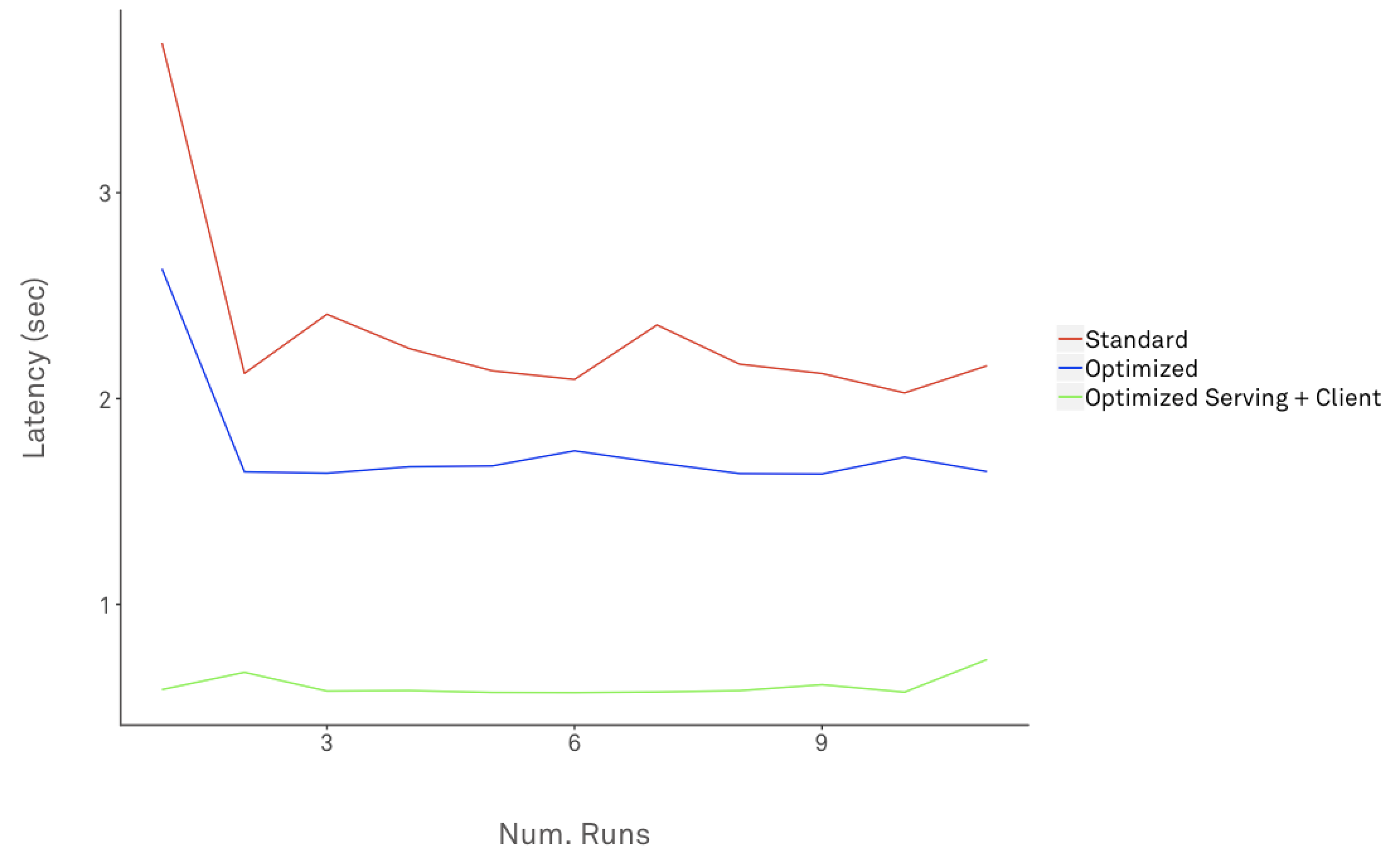
The average latency dropped from standard Tensorflow Serving to optimized version by ~70.4%.
Optimizing Prediction Throughput
Tensorflow Serving can also be configured for high throughput processing. Optimizing for throughput is usually done for "offline" batch processing where tight latency bounds are not a strict requirement.
Server-side Batching
Server-side batching is supported out of the box by Tensorflow Serving as mentioned in docs here.
The trade-offs between latency and throughput are governed by the batching parameters supported. Tensorflow Serving batching works best to unlock the high throughput promised by hardware accelerators.
To enable batching, set --enable_batching and --batching_parameters_file flags. Batching parameters can be set as defined by SessionBundleConfig. For CPU-only systems, consider setting num_batch_threads to number of cores available. See here for batching configuration approaches with GPU-enabled systems.
Upon reaching full batch on server-side, inference requests are merged internally into a single large request (tensor) and a Tensorflow Session is run on the merged request. Running a batch of requests on a single Session is where CPU/GPU parallelism can really be leveraged.
Some general use-cases to consider for batch proce Tensorflow Serving Batching:
- Use asynchronous client requests to populate batches on server side
- Speed up batch processing by putting model graph components on CPU/GPU
- Interleave prediction requests when serving multiple models from same server
- Batching is highly recommended for "offline" high volume inference processing
Client-side Batching
Batching on the client-side is grouping multiple inputs together to make a single request.
Since the ResNet model expects input in NHWC format (first dimension being the number of inputs), we can aggregate multiple input images into a single RPC request:
...
batch = []
for jpeg in os.listdir(FLAGS.images_path):
path = os.path.join(FLAGS.images_path, jpeg)
img = cv2.imread(path).astype(np.float32)
batch.append(img)
...
batch_np = np.array(batch).astype(np.float32)
dims = [tensor_shape_pb2.TensorShapeProto.Dim(size=dim) for dim in batch_np.shape]
t_shape = tensor_shape_pb2.TensorShapeProto(dim=dims)
tensor = tensor_pb2.TensorProto(
dtype=types_pb2.DT_FLOAT,
tensor_shape=t_shape,
float_val=list(batched_np.reshape(-1)))
request.inputs['inputs'].CopyFrom(tensor)For a batch of N images, the output Tensor in the response would have prediction results for the same number of inputs in request batch, in this case N = 2:
outputs {
key: "classes"
value {
dtype: DT_INT64
tensor_shape {
dim {
size: 2
}
}
int64_val: 238
int64_val: 121
}
}
...Hardware Acceleration
A few words on GPUs.
For training, parallelization can be exploited by GPUs more intuitively, since building deep neural networks requires massive calculations to arrive at optimal solution.
However, this is not always the case for inference. Many times, CNN's will get inference be sped-up when graph execution steps are placed on GPU devices. However, Picking hardware that optimizes the price-performance sweet spot requires rigorous testing, in-depth technical and cost analysis. Hardware accelerated parallelization are more valuable for "offline" inference batch processing (massive volumes).
Before inviting GPUs to the party, consider the business requirements with a thorough cost (monetary, operational, technical) analysis over benefits (strict latency, high throughput).
Wrapping up
To experience ML-driven video streaming quality settings, try out Mux Video. Or if you’re interested in working on projects like this, check out our openings!
Photo by Fancycrave on Unsplash


