
There’s nothing quite as invigorating as getting your work out into the world and in the hands of your users. You spend hours getting the design just right, converting the mockup over to code, and testing the new functionality. You’re confident that it all works as it should. Ship it!
There’s only one problem: Your users don’t always use your products as intended. In fact, some of them will intentionally try to break your intended usage. And some will go so far as looking for exploits to take advantage of.
Not so invigorating anymore, is it?
This exact situation came up recently here at Mux with our documentation feedback form. Here’s how we were able to get ahead of the trouble and save our feedback form with a little help from Edge Config at Vercel.
Developer experience means listening to customers
At Mux, we take our developer experience seriously, as we think it is a crucial component to providing a good developer-focused product, one that developers like to use and will recommend to their friends. We believe documentation is an easily overlooked part of the developer experience, and we’ve spent time making sure we’re providing the best experience we can with our documentation.
We moved to a home-built docs site almost two years ago when we wanted more control over the docs experience, and we upgraded our docs site just a month ago to address some limitations we had noticed (and add in that sweet, sweet dark mode).
If you’re interested in what makes good docs, I strongly suggest reading the above two posts. Dylan and Darius did a great job of covering all the components of good documentation. Rather than rehash things, I’m going to quote what Darius wrote:
Good docs come from quality content and excellent usability. Quality content answers your users’ questions with simple and accessible language. Excellent usability connects your users to the content they’re looking for.
“Quality content answers your users’ questions with simple and accessible language.” This is where I want to focus.
Ideally, every piece of content you have should answer the user’s question, be that with a guide, an API reference, or some other piece of information. Let’s say you’ve done your user research, and you’ve written guides specifically to help users solve their problems.
Now, how do you know it’s actually working?
User feedback is crucial
Documentation is never complete, and you should always be iterating on your documentation. One of the best ways to know where improvement is needed is to let your users tell you what’s working and what is not.
To that end, we built a small feedback form in our docs site, allowing users to tell us, for each guide and post, whether the content was helpful, and also provide specific comments.
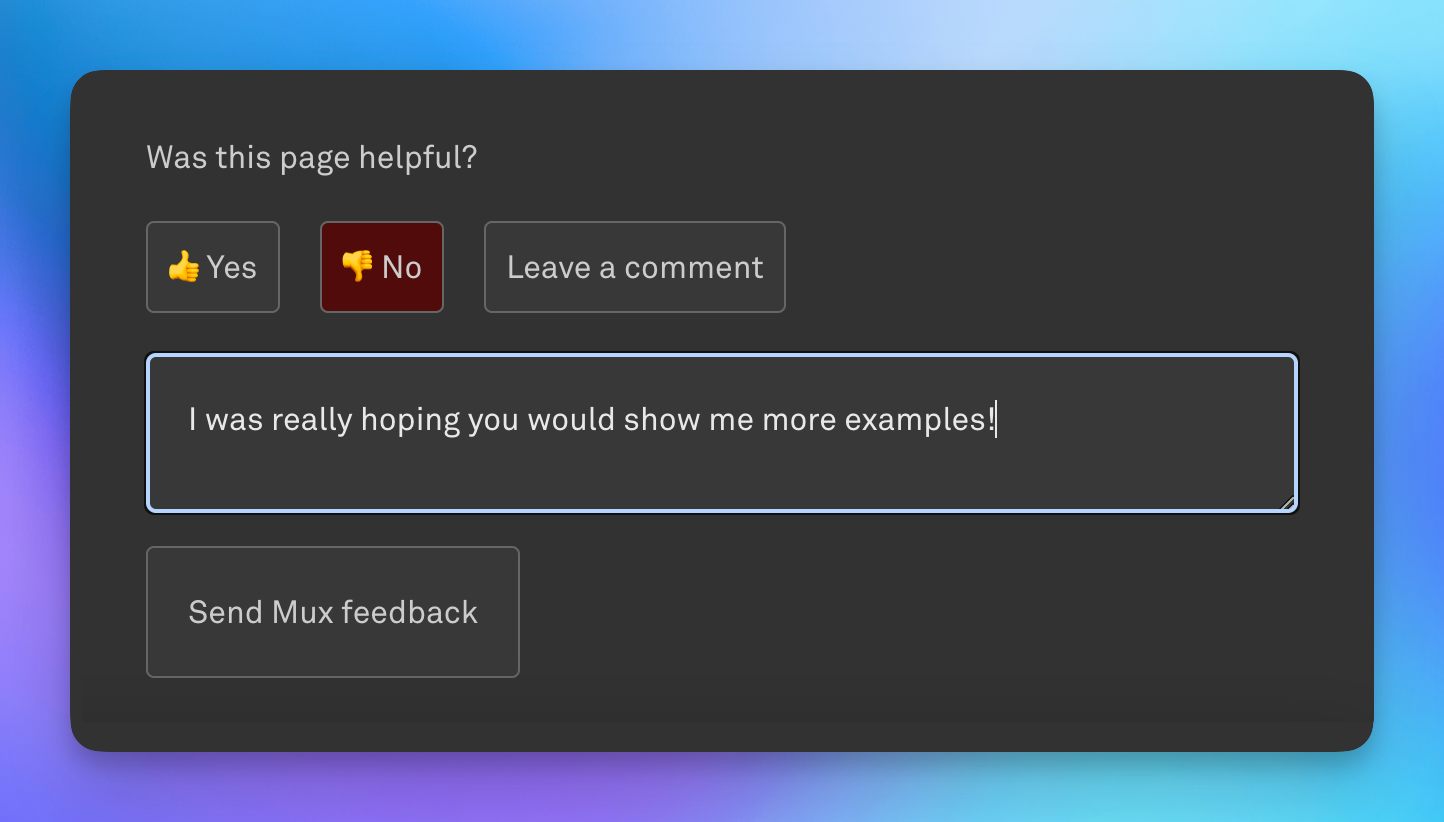
This form is great, and we’ve built a process to re-incorporate this feedback into our docs, which we feel has added greatly to our doc quality. Behind the scenes, this form hits a Vercel Serverless Function that we set up to create a row in an Airtable base we have just for collecting documentation feedback. Every new row also pings a dedicated Slack channel so that we’re aware of the new feedback and can take action.
That simple setup has served us well… until recently.
The internet ruins everything
There are countless memes out there about how the internet has a tendency to find ways to ruin even the most harmless of ideas. Having worked in video for a decade, I can tell you those memes exist for a reason.

We started to see the number of submissions spike, getting hundreds of “pieces of feedback” an hour that were clearly not coming from users. If you’ve worked with public form submissions or on public APIs, you can guess what we saw first: script/SQL injection, or other forms of attack on relatively known security vulnerabilities.
We had initially built in some sanity checking for the fields (e.g., rejecting submissions where a boolean wasn’t a boolean), and we already protected our system from SQL and code injection, so the system was safe. But those invalid submissions were flooding Airtable and hiding the useful feedback that we were getting in the flood. And, because we cared about each piece of feedback so much as to get a Slack notification for every submission, you can imagine how annoying that got.
So we decided to stop it.
Stopping the flood: attempt #1
There are some standard mechanisms people use to guard against these extra form submissions, including rate limiting that API endpoint or using something like reCAPTCHA, and we considered those approaches first. We opted against rate limiting as we did not want to introduce Redis or some other stateful dependency; we wanted to keep this as simple as possible with the fewest moving parts.
We chose to avoid a reCAPTCHA solution because we wanted to limit any friction for actual users providing feedback. Asking for feedback from a user already involves effort and good will on the user’s part, and adding another potential step to that process felt like it would limit the volume of feedback.

After those options, given that we were seeing many repetitions of the same attack vector (such as the same SQL injection, or the same attempt to run arbitrary code on our servers), our next thought was to build a system that blocks repeated submissions of the same known-bad feedback, as it was the simplest approach at the time. We exported the rows of feedback from Airtable, and with a little sorting and grouping, pulled out a list of about 500 unique messages that had been submitted that we knew were invalid feedback.
Using this list of known-bad messages and the patterns we found in them, we implemented a set of checks to ensure that the following wouldn’t be passed on to Airtable:
- Submissions without a valid URL for the page it was supposed to be about
- Submissions that included no information
- Submissions that were repetitions of the known attack vectors
This worked well, and we returned to normal with regard to receiving actual feedback that we wanted to pay attention to. When we saw new attack-type messages come in, we’d update that list of known-bad messages, and redeploy to block further submissions of the same. This was a bit of a manual process, and it did require a PR and deployment of our docs site to update the list, but it worked well enough. Success!

Just this past week, however, we started to see another pattern of feedback, lighting up Slack incessantly and pushing us to take further action. In this case, it looked like there were a number of people using automated vulnerability detection software (such as Burp Suite, the culprit in our case) to crawl our docs site and submit empty “yes this was helpful” feedback, on every single page on the site. I detest unread channels in Slack (it’s a problem, I know), so the constant notifications alone were enough for me to take action — not to mention the problem of these messages diluting the actual valuable feedback from users. We couldn’t let this stand.
Stopping the flood: attempt #2
Since we’d already blocked repetitive messages, and in this case there was no message at all, we had to explore a different mechanism for filtering out this bad feedback.
The first idea I had was to add some very basic header-based blocking in our function. Sometimes, if these testing tools are run outside of browsers, they’re nice enough to include some identifying information in the headers. While I was in the middle of adding this quick check to a few known headers, someone else on our team had the smart idea of blocking by IP address. In this most recent flood, we noticed the messages were coming from a small handful of IP addresses, so an IP denylist, alongside the header blocking, is what we decided to go with.
If you recall, the downside of our first approach was the manual nature of updating our blocked messages, as well as requiring a pull request and deploy to get the updated list out in production. We anticipated multiple IP addresses being used, and we didn’t want to require a full deploy each time we wanted to update our denylist. To get around this, we turned to Vercel’s new feature, Edge Config.
Edge Config is a globally distributed key-value store available on Vercel’s Edge Network. It allows you to manage data through their UI or API. This allows you to quickly read data from your application at ultra low latency, without the need for a separate database. Vercel themselves put it best for our use case here:
You can use it to check feature flags, initiate redirects, or block malicious IPs at the speed of the Edge, without hitting upstream servers.
The Getting Started guide Vercel provides is exceptionally straightforward (great developer experience right there!), but I’ll recap the steps here:
- Navigate to your project in Vercel and select Edge Config along the top nav.
- Create a new store in the UI. We called it docs-feedback-store in this case, though you can use a more generic store for your project, or you can use a more generic store across projects. There are limits depending on the level of your Vercel account, so exactly how you architect your stores will vary depending on your use case.
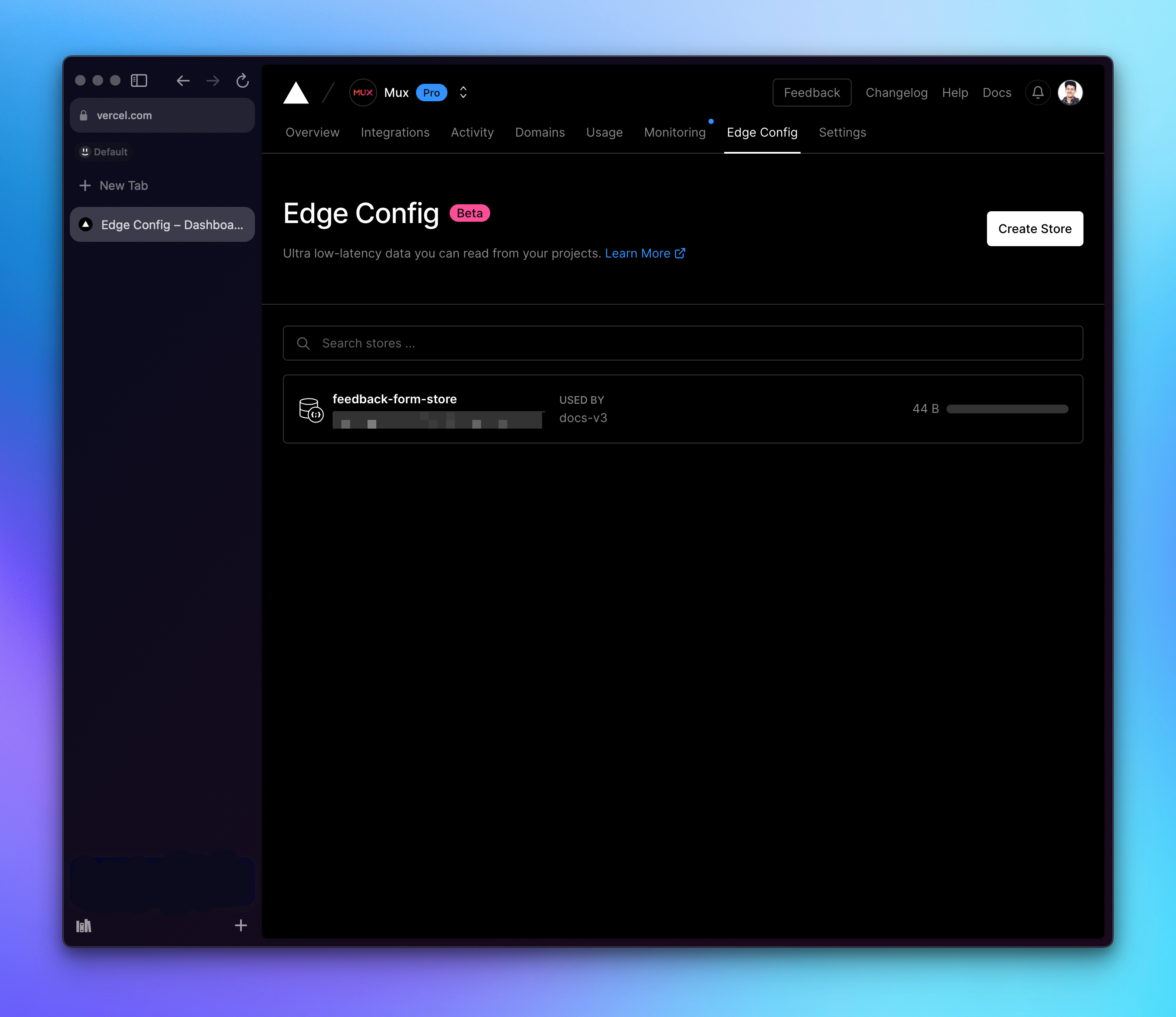
- Creating the store and connecting it to your project will automatically configure EDGE_CONFIG as part of your Vercel env, which makes it exceptionally easy to use Vercel’s SDKs in your functions to access the data. Because we’re only using one store in this example, we don’t need to work with connection strings, but Vercel’s documentation covers all the options you need for that.
- In our case, we added a key to the store, named bad_ips, that contains an array of IP addresses (as strings — and no, these are not the real IPs we’re blocking).
{
"bad_ips": [
"1.1.1.1",
"8.8.8.8"
]
}- Then, inside our function, we need to import the SDK (the connection being managed automatically by the EDGE_CONFIG env variable) and read the data where we care about it:
import { get } from '@vercel/edge-config';
export default async function Feedbacks (req, res) {
const badIPs = await get('bad_ips');
if (badIPs?.contains(req.headers['x-real-ip']) {
// Do what you want here to the response
// We choose to send a 200 and not indicate an issue.
// if you’re feeling cheeky, maybe sleep a little…
res.status(200).json({ message: 'thanks' });
}
// continue on with normal handling
}And that’s it! Now we can update the list of bad IPs at any point in our Edge Config Store without having to redeploy our project at all. This will propagate across Vercel’s Edge Network, and malicious IP addresses will be blocked.
This is very simple thanks to the Edge Config; otherwise, we’d have to build out a database of our own, make that available, and query it every time this function is hit. As I said before, we’re big fans of a great developer experience, and it’s great to work with products that feel the same way.
From start to finish, this took less than an hour to implement and deploy, and within 2 days of deployment, we’d updated the list and started using this across other functions where we want to block the same IPs. We’re just starting to dig our toes in, but I already have a growing list of improvements we can make to our systems using Edge Config.
We love feedback again!
That feedback form is still live on every guide within docs.mux.com, and we’d love to hear any feedback you have! Of course, we’d prefer if you don’t spam us, because we’d prefer to not block you and miss out on useful feedback you might have — but if you do make us block you, at least now we can do it easily 😉


