
I saw this incredible video the other day. There was this one moment in it that you’ve just gotta see. Here, let me pull it up.
Ugh. Hold on, sorry. I know it’s in here somewhere. It’s not this part. I think it was afterwards. Hmm. Or maybe it was a different video?
We’ve all been there. Video is an amazing storytelling medium, but recalling the memorable moments embedded within them can prove to be challenging. Lucky for us forgetful humans, LLMs have made this task considerably easier.
After rolling out @mux/supabase, we wanted to build something fun, so we decided to take a crack at semantic video search.
The idea is simple – you type in a query and get a list of video clips as search results. Click on a clip and it takes you straight to the spot in the video that matches your query.
Perfect timing for Demuxed.
Demuxed is the conference for video developers, and it’s been going on a while – 10 years. And it’s happening this week in London. Shoutout Demuxed!
And because it’s been going on for a while, we have the perfect corpus of video content to pull from – the 270-ish video archive.
So now we have an idea: Semantic video search, and a muse: Demuxed. And we have our tech stack:
- Mux for video infrastructure (of course). This gives us:
- A place to store all our videos
- Auto-generated captions for each video, which also gives us a time-stamped transcript in the form of a .vtt file.
- Mux Player, which has all the necessary player functionality we want, including timeline hover previews and chapters.
- Supabase for application infrastructure (Postgres, handling webhooks from Mux)
- Next.js for React frontend
See the final product here at supasearch.mux.dev and the code on Github at muxinc/supasearch.
Let’s dive in. First, the data model
Videos table
Anyone who has built something with Mux has probably set up their database with a videos table. Generally, each row in the table corresponds to a single video in their domain model and that video has a mux_asset_id column.
This approach is great because the concept of a "Video" in your system is only loosely-coupled to a Mux asset. You can also keep the same "Video", and point it to a different Mux asset later, if you want to. We’ll do that here too. Our videos table has:
- title
- description
- transcript
- topics
- chapters
- mux_asset_id (a foreign key that points to the assets table in the mux schema that was set up by the @mux/supabase integration
Video chunks table
Since our videos are pretty long (20-30 mins or so), we’re going to be breaking the videos into chunks. Each chunk of video consists of ~45 seconds of content. No real magic to why we picked that number, we just want to make sure each chunk is small enough to create an embedding with OpenAI.
Each row in the video_chunks table has:
- chunk_index (sequence number)
- video_id (foreign key pointing back to the videos table
- start_time (seconds)
- end_time (seconds)
- chunk_text (the text, derived from the transcript)
- embedding (vector created from OpenAI’s text-embedding-small model)
Saving data to Supabase
In order to do nearly anything with the videos, we’ll need transcripts. In this case, we’ll use Mux's auto-generated subtitles feature to generate transcripts in english: https://www.mux.com/docs/guides/add-autogenerated-captions-and-use-transcripts
We’ll send that transcript to gpt-5 in order to generate the basic information about the video: title, description, topics and chapters and save that to the database. And then break up the video into chunks and create embeddings for each chunk. Here’s how saving data to the database works.
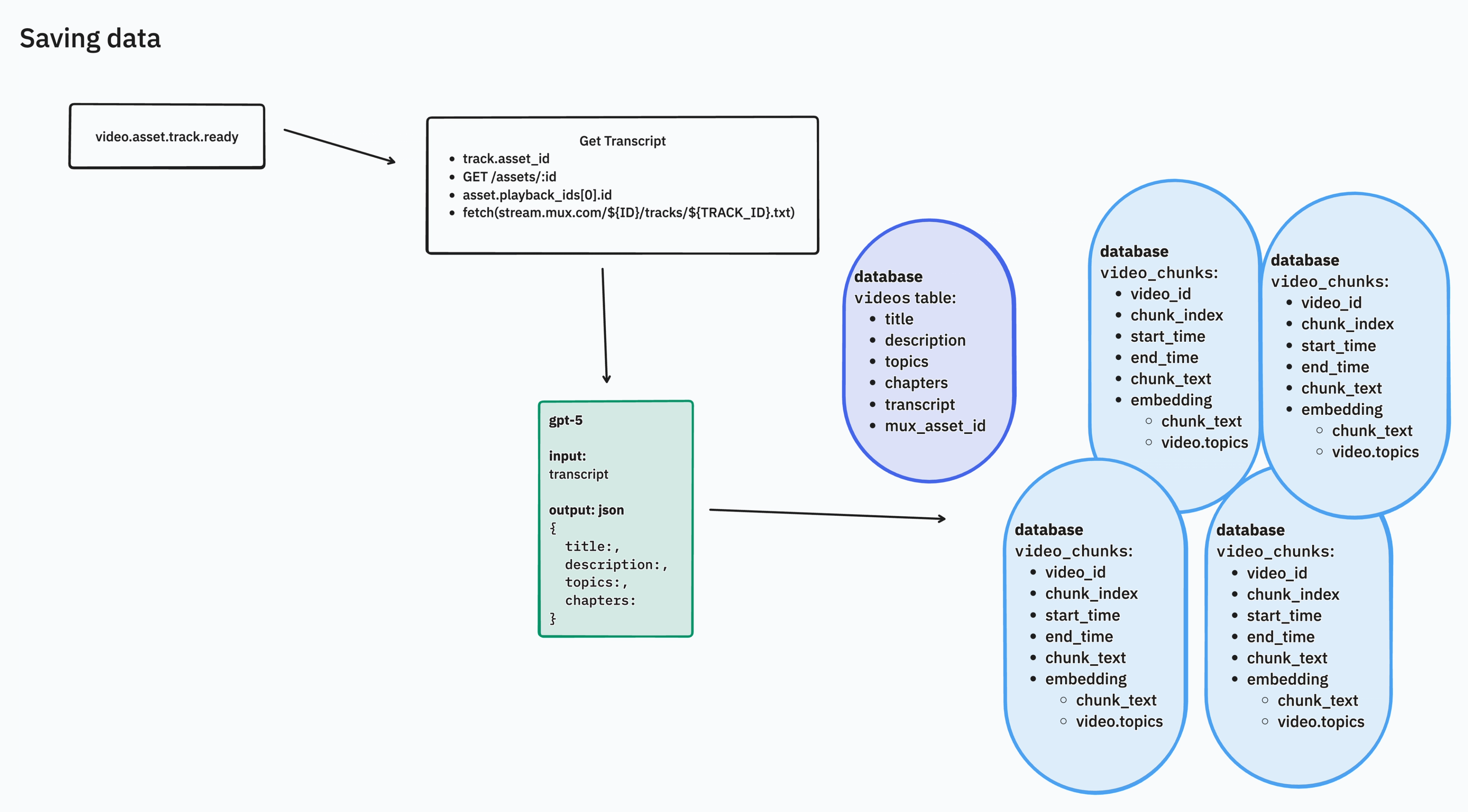
The migration in Supabase looks like this
-- Enable the "vector" extension for embeddings
create extension if not exists vector;
-- Videos table for metadata
create table public.videos (
id uuid not null default gen_random_uuid() primary key,
title text,
description text,
transcript_en_text text,
transcript_en_vtt text,
mux_asset_id text not null references mux.assets(id) on delete cascade,
topics text[],
chapters jsonb,
created_at timestamp with time zone default now(),
updated_at timestamp with time zone default now()
);
-- Video chunks table for searchable segments with embeddings
create table public.video_chunks (
id uuid not null default gen_random_uuid() primary key,
video_id uuid not null references public.videos(id) on delete cascade,
chunk_index integer not null,
chunk_text text not null,
start_time numeric not null,
end_time numeric not null,
visual_description text,
embedding vector(1536), -- OpenAI text-embedding-3-small
created_at timestamp with time zone default now()
);There’s one key detail about the migration which is that the embedding column on the video_chunks table uses the pgvector extension. It’s key here that:
- The number of dimensions (1536) matches the number of dimensions in the embedding model we’re using to create the values (OpenAI text-embedding-3-small)
- At query-time, when we generate query embeddings, we have to use the same embedding model that we used to save the embeddings.
Since we are using @mux/supabase with a workflow to trigger when the video.asset.track.ready event fires, then any new videos added to our Mux account will get automatically created in the database with all the data we need. So as soon as the recordings are ready for this year, all we have to do is upload them to Mux and they’ll be indexed and added to the database and ready to query.
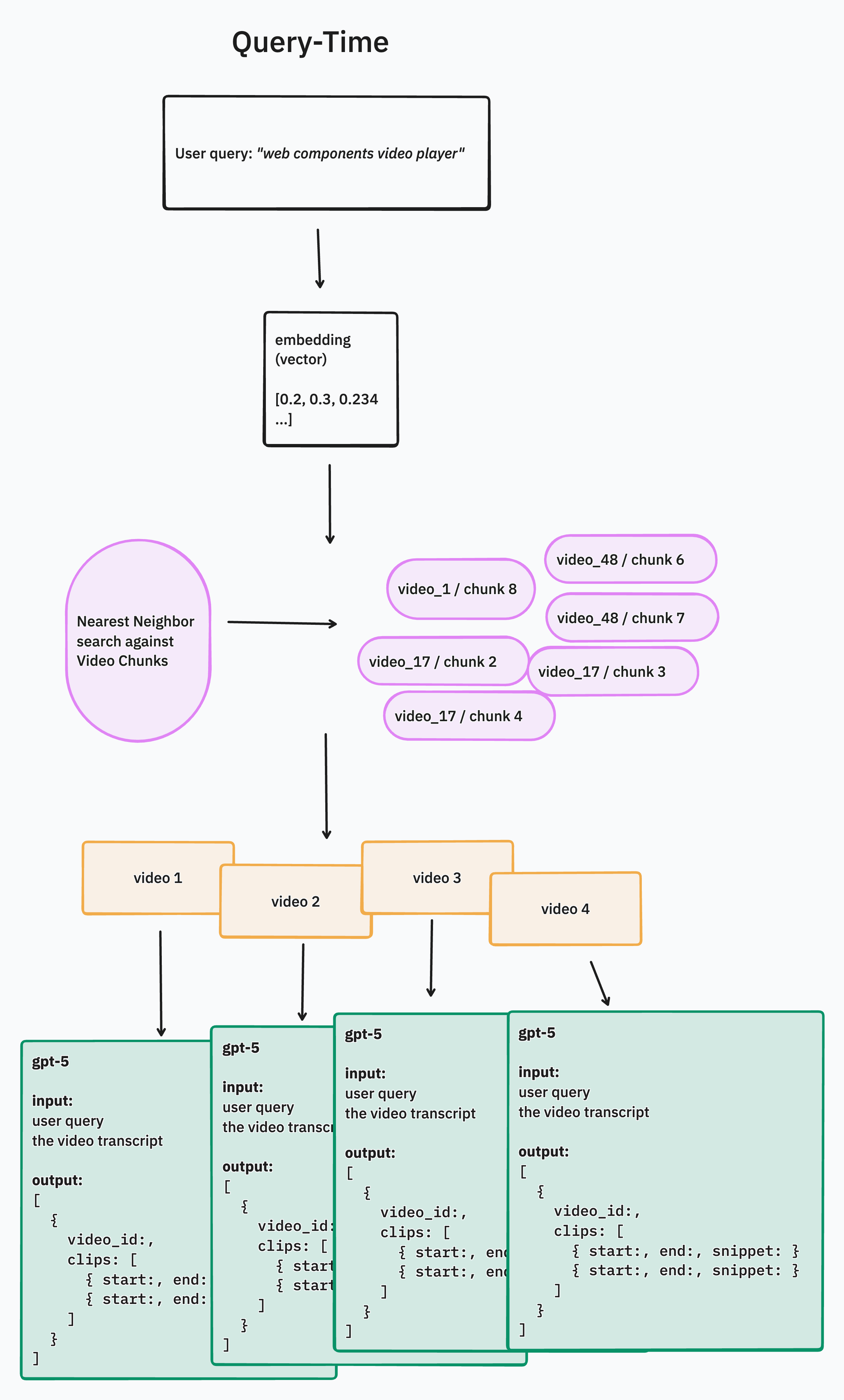
Querying data and generating results
The next steps to query and generate results. Let me first say that this step is highly specific to your domain and your use case. The way you index your data, rank results, filter by metadata, etc. will depend a lot on your use case and how you expect people to perform searches. What we have here is a relatively simplistic Retrieval-Augmented-Generation (or RAG) approach.
The basic idea is, we will:
- Convert the user's query into an embedding vector
- Query the table of video_chunks and grab a bunch of them
- Map the matching video_chunks results back to the videos they belong to
- Return a list of the videos to the user
- Kick off a background job for each video in the list to extract clips based on the user's query & the transcript. A single video will pull up to 3 relevant clips
Evaluating how well this works
The cool thing about this approach with embeddings is that it is matching based on the semantic meaning of the query. So a query for "smell" will pull up Phil's smell-o-vision talk AND Jon’s talk about the Science of Perception – where he talks about human vision, hearing and other human-sense related things. If we’re purely doing a string match or some kind of root-word query that takes into consideration word stems and things like that, we’d be getting quite different results. For certain things, this works really well.
How you might improve this
I can see a number of ways you may want to build this out for other use cases, let’s run through a few ideas (in no particular order):
Re-write the user's query
Oftentimes, users are not great at querying. They might say one thing and mean another. One way to improve this system is to have an AI step that takes what the user entered and re-writes it to be better for the purpose of retrieval. This is fairly common. We can potentially add this when we see how people are querying it, what the results are and maybe we can make that better.
Finding clips is slow
Finding clips right now is slow. This happens in parallel, for each video in the list. We can add more concurrency here, use a faster model (right now we’re using gpt-5-nano), or send less context along with the prompt so that we get a response back from OpenAI faster.
Add visual data to the embedding
For our Demuxed use case, since these are conference talks, mostly everything we care about is in the transcript. But if you have videos of your children, for example, you may want to index visual data that is not in the transcript. For example:
- "Birthday party", "ice cream", "cake", "balloons", for a video of your kid’s birthday party. These are things that appear visually in the video, but are not represented in the transcript
- "Soccer ball", "field", "game", "park" for a video of your kids soccer game.
This is fairly straight-forward to do with Mux since you can Get thumbnails from the asset and send them as image inputs to extract text. Or even download the full Static rendition (mp4) of the asset and use a model to analyze that.
If you look closely in the schema you’ll see we have a visual_description column on the video_chunks table. So we already laid the groundwork if you want to try this.
Use a combination of database-filtering AND semantic search
One thing that embeddings and semantic search is not good at is filtering. For example if you say "Demuxed 2019 HEVC" by default it’s not going to filter down to only results from Demuxed 2019. You could add that in a couple of ways:
- Explicit filters in the UI (a dropdown to select one or more Demuxed years), and then apply that filter in the retrieval step, before the semantic search.
- Use an AI step, similar to re-writing the user's query to extract any known-filterable parameters. Your prompt would have to know what filters are available, and then be smart enough to take the user's natural language query and split it out into the filter parts and the semantic search part.
This is fairly straight-forward too, and a common approach when building a natural language querying interface.
Let us know what you think
Let us know what you think! If you have built something like this for video, we’d love to hear about it, how you did it. What worked, what didn’t work and what you learned. And hey, whatever you built could end up being a Demuxed talk!


