
A strength of stream-processing systems like Apache Flink is the ability to have an application span a large number of hosts with ease. However, running a stateful distributed application presents a challenge in performing administrative tasks across the cluster without incurring downtime. In this post, I’ll describe how we’ve solved this problem at Mux by introducing a control stream to our Flink application.
How Did We Get Here?
Stream processing applications are typically fed by one or more stream sources. Examples of stream sources include AWS Kinesis, Apache Kafka, or a raw socket. It’s natural that someone would begin a stream-processing application with a single data stream source. Nice & simple, right?
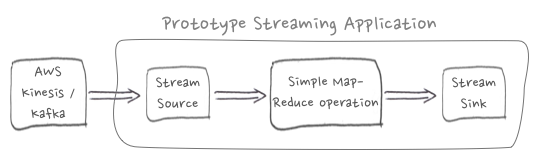
It doesn’t take long for you to start inventing additional interesting calculations to run on the data from your stream source. That cute little prototype has ballooned into a complex graph with multiple outputs.
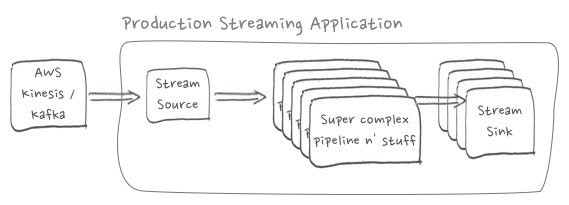
Some applications might include operators with raw state or rolling fold state. In the case of Apache Flink, this state will be included in checkpoints & savepoints written to storage. The state will be restored to these operators automatically if recovering from a critical job failure or starting the job from a savepoint.
A drawback to the state persisted by Flink and other stream-processing systems is that it’s written in a non-portable format. If you’re hoping to inspect your application state from savepoints, then good luck. Not gonna happen.
That little streaming application that had such humble beginnings is now a stateful, opaque behemoth. What’s going on in here?
Cutting Windows in the Black Box
Anyone who’s spent even a little time working on machine-learning systems has resorted to some variation of the statement, “it works, just trust me,” when explaining actions taken by the system. It feels awful, probably because it is.
A book that’s in heavy rotation at Mux is “High Output Management” by Andy Grove. Aside from being a very talented engineer and co-founder of Intel, Andy Grove was an all-around great human being. Grove was a strong proponent of measuring all-the-things:
“The black box sorts out what the inputs, the output, and the labor are in the production process. We can improve our ability to run that process by cutting some windows in our box so that we can see some of what goes on within it. By looking through the openings, [...] we can better understand the internal workings of any production process and assess what the future output is likely to be.” (Andy Grove, "High Output Management")
Similarly, we should be able to monitor and inspect the inner-workings of our streaming application. Offline analysis of models built through online machine-learning can boost confidence in their correctness and guard against regression defects.
At Mux we needed the ability to instruct the Flink application to dump the state of pipeline operators responsible for online machine-learning. The state should be written to AWS S3 storage in a portable format (e.g. CSV, JSON). We should be able to do this at any time, on-demand and with deterministic results.
Introducing a Control Stream
Control streams (sometimes called control channels) are found in many communications systems including LTE cellular networks, trunked digital radio systems used by police & fire departments, and the Real-Time Messaging Protocol (RTMP) used by video streaming services. Potential uses for control-streams in a streaming application include triggering the application to reload configuration, clear caches, or reload models from storage. In our case, we’ll drop a message into a control stream and allow it to propagate throughout relevant Flink operators in our distributed application. As an analogy, imagine placing drops of colored dye in moving water and seeing it fan out downstream.
Our Flink application is driven by an existing Kinesis stream source that reads Protobuf-encoded messages that include video playback event details; this is not the right place to introduce control fields. We needed a new stream-source and Protobuf specification for control messages.
We introduced a RabbitMQ queue to deliver control messages to a new control stream source in the Flink application. RabbitMQ was chosen because the volume & frequency of control messages was too small to justify the monetary cost of a new Kinesis stream. It also helped that Flink has built-in support for RabbitMQ and was easy to work with.
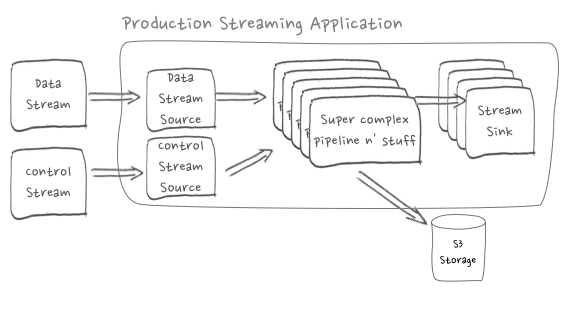
We’ve got a checkpointed flat-map operator that performs a stream-join on the data and control streams. The operator defines methods to work on each stream source and the accumulated state. This makes it possible for the flat-map operator to handle a control message to dump the accumulated state built from data stream messages.
Results
Introducing the control stream was an easy addition and has performed great. Exporting machine-learning models to storage has made it possible to analyze and validate models offline. Our Flink application can also load the models from S3 if starting without state, which can happen if the application pipeline is modified in a way that breaks compatibility with earlier versions, or in the event of a catastrophic failure that takes down the HDFS cluster where checkpoints and savepoints are stored.
Keep following the Mux Blog for more posts related to Apache Flink and real-time analytics! You can also follow us on Twitter to catch our blog posts as soon as they go live.
“Railway tracks in the sunset. Taken at Frankfurt Central Station.” by Arne Hückelheim is licensed under CC BY-SA 3.0



{kind=link}